Still Using GPT-4o for Everything? (How to Build an AI Orchestra & Save 90%)
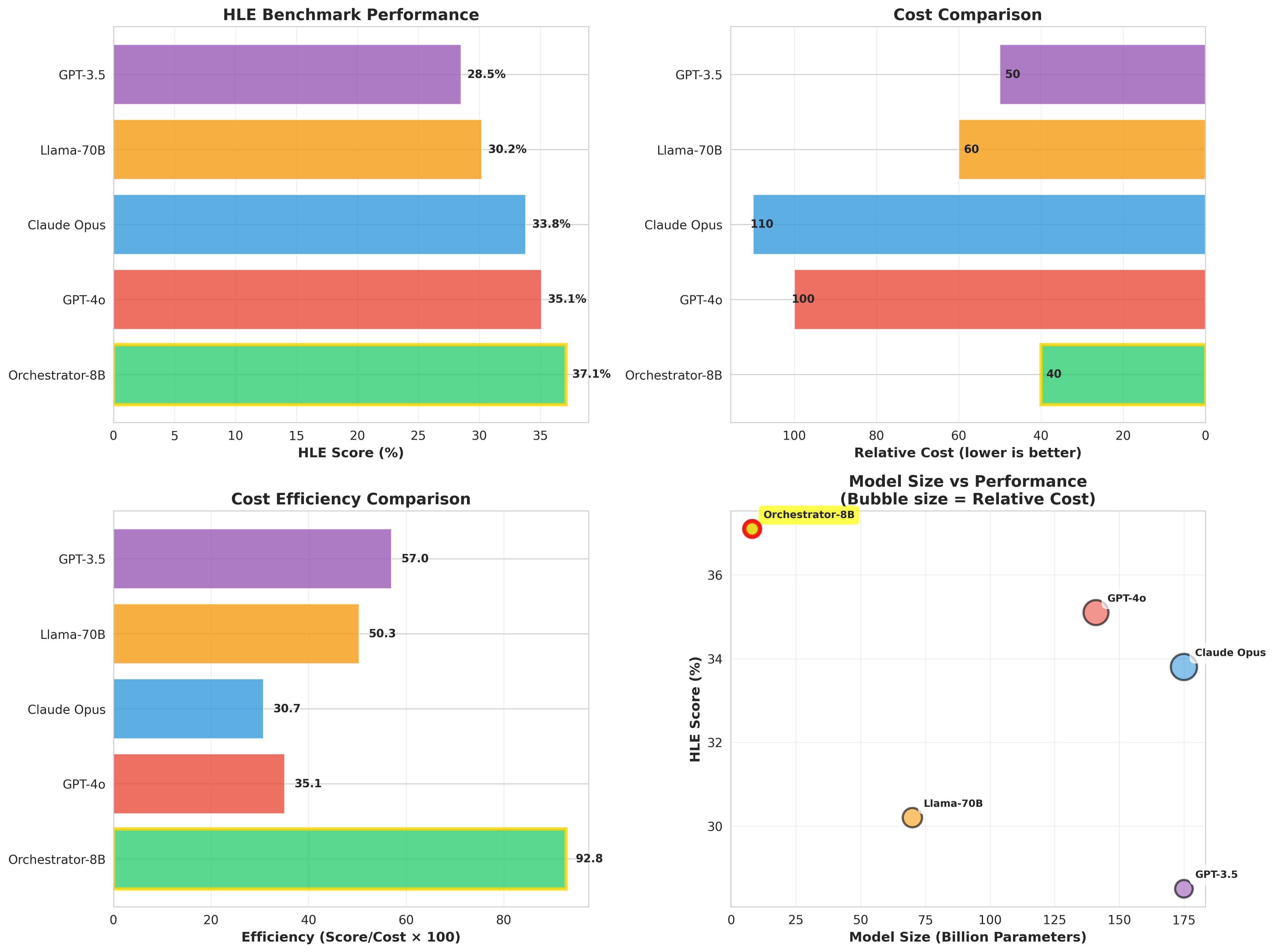
An 8B model as conductor routes queries to specialized experts based on difficulty. ToolOrchestra achieves GPT-4o performance at 1/10th the cost using a Compound AI System approach.
"Don't use a sledgehammer to crack a nut."
Have you checked your API bill this month? Is it full of gpt-4o charges?Chances are, 80% of those queries could have been answered by a toddler (a small model).
Enter ToolOrchestra. It introduces a paradigm shift: An 8B parameter "Orchestrator" that intelligently routes queries to the right expert (e.g., a 72B Math model or a 32B Coding model).
The result? Matching GPT-4o performance at 1/10th of the cost.
📚 Table of Contents
- Introduction: The "Cost-Performance" Dilemma
- Why are we addicted to expensive models?
- Monolithic vs. Compound AI Systems
- What is ToolOrchestra?
- Core Concept: The Conductor and the Musicians
- Architecture Overview
- Deep Dive 1: Secrets of the Orchestrator
- How does an 8B model make decisions?
- Beyond Prompt Engineering
- Deep Dive 2: GRPO (Group Relative Policy Optimization)
- Why Reinforcement Learning?
- Reward Function Analysis: Accuracy vs. Efficiency
- The GRPO Algorithm Explained
- Code Walkthrough
- Dissecting
run_hle.py - Understanding the Logic via Mock Demo
- Dissecting
- ROI Analysis (Cost Efficiency)
- GPT-4o vs. ToolOrchestra Cost Comparison
- Per-Token Unit Economics
- Limitations & Solutions
- Latency Challenges
- Infrastructure Complexity
- Conclusion: The Future is "Team Play"
1. Introduction: The "Cost-Performance" Dilemma
1.1. Why are we addicted to expensive models?
In 2024, the default choice for AI developers is GPT-4o or Claude 3.5 Sonnet. Why? Because they simply work.
However, from a business perspective, this is often a disaster.
When a user just says "Hello," your backend spins up the most expensive GPU clusters available. It's like driving a Ferrari to the convenience store just to buy water.
1.2. Monolithic vs. Compound AI Systems
- Monolithic AI:
- One genius model does it all (e.g., GPT-4).
- Pros: Easy implementation. Just one API call.
- Cons: Expensive. Slow. Overkill for simple tasks.
- Compound AI System:
- A system where multiple specialized models collaborate.
- Pros: Cheap. Fast. Flexible.
- Cons: Complex implementation. Requires a Router to decide "who does what."
ToolOrchestra is an elegant implementation of this Compound AI System philosophy.
2. What is ToolOrchestra?
2.1. Core Concept: The Conductor and the Musicians
Just like a real orchestra:
- The Conductor (Orchestrator):
- Role: Doesn't play an instrument. Analyzes the flow and directs "who should play now."
- Model: Qwen2.5-8B (Lightweight & Fast).
- Function: Analyzes user queries to determine difficulty and type.
- The Musicians (Experts):
- Role: Execute specialized tasks under the Conductor's direction.
- Models:
- 🎻 Math Expert: Qwen-Math-72B (Complex Calculus, Algebra)
- 🎹 Coding Expert: Qwen-Coder-32B (Python Scripting)
- 🥁 Logic Expert: Llama-3.3-70B (Reasoning, Common Sense)
- 🔔 Search Expert: Search Tool (External Knowledge Retrieval)
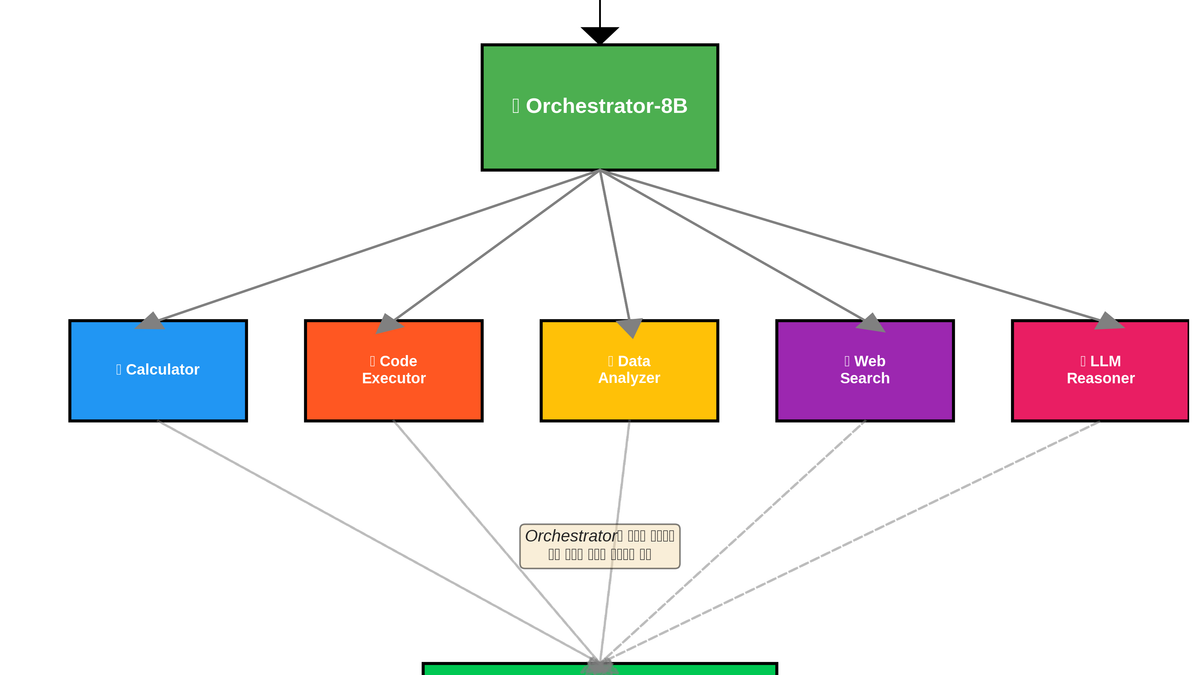
2.2. Architecture Overview
graph TD
User[User Question] --> Orchestrator[Orchestrator (8B)]
Orchestrator -- "Easy / Chat" --> DirectAnswer[Direct Answer (8B)]
Orchestrator -- "Math Problem" --> MathExpert[Math Expert (72B)]
Orchestrator -- "Coding Task" --> CodingExpert[Coding Expert (32B)]
Orchestrator -- "Need Info" --> SearchTool[Search Tool]
MathExpert --> Orchestrator
CodingExpert --> Orchestrator
SearchTool --> Orchestrator
Orchestrator --> FinalAnswer[Final Answer]The key here is that the 8B model acts as a Gatekeeper.
It handles simple queries itself, avoiding waking up the 72B giants. This is where 80% of the cost savings come from.
3. Deep Dive 1: Secrets of the Orchestrator
"Can't I just use a prompt to say 'If math, call math model'?"
Yes, you can. But ToolOrchestra is smarter than that.
It possesses Metacognition: "Can I solve this myself? Or do I need to call the big boss?"
3.1. How does an 8B model make decisions?
The 8B Orchestrator was trained on tens of thousands of problems (GSM8K, MATH, etc.).
During this process, it learned an Intuition:
- Confidence: "I've failed this type of problem before. Better pass it to the 72B expert."
- Cost Awareness: "The 72B expert is expensive. Let me try solving it first; if I fail, then I'll call for help."
3.2. Beyond Prompt Engineering
| Feature | Prompt Engineering (LangChain Router) | ToolOrchestra (RL Trained) |
|---|---|---|
| **Method** | Rule-based ("If X, then Y") | Data-driven (Trial & Error) |
| **Flexibility** | Brittle on edge cases | Probabilistically handles ambiguity |
| **Optimization** | Manual rule tuning required | Self-improves with more data |
4. Deep Dive 2: GRPO (Group Relative Policy Optimization)
The technical highlight of this project is GRPO.
This is the Reinforcement Learning algorithm used to train the 8B model into a "Smart Conductor."
4.1. Why Reinforcement Learning?
Supervised Fine-Tuning (SFT) isn't enough.
SFT teaches the model to "mimic the correct answer," but it struggles to teach "strategic decision-making among multiple tools."
To learn strategy, you need Reward-based Reinforcement Learning.
4.2. Reward Function Analysis: Accuracy vs. Efficiency
The reward function is designed to balance two conflicting goals:
$$ R = R_{accuracy} + \lambda \times R_{efficiency} $$
💡 TL;DR:
"You got the right answer? Great! But... you spent too much money? Penalty!"
It trains the model to be cost-conscious.
- $R_{accuracy}$: Did the final answer match the ground truth? (+1 / 0)
- $R_{efficiency}$: How few tokens (cost) were used?
If the 8B model calls the 72B model for a simple "1+1=?" question:
- It gets $R_{accuracy}$ (Correct),
- But it gets a huge penalty on $R_{efficiency}$.
As a result, the model learns "Economic Sense": How to get the right answer at the lowest possible cost.
4.3. The GRPO Algorithm Explained
PPO (Proximal Policy Optimization) is great but memory-intensive because it requires a Value Function.
GRPO improves this by using Group Relative Evaluation.
- Sampling: For one question, the 8B model tries multiple strategies (Actions).
- Strategy A: Solve directly.
- Strategy B: Call 72B.
- Strategy C: Use Search.
- Evaluation: Evaluate the outcome (Accuracy, Cost) of each strategy.
- Update: Increase the probability of strategies that performed better than the group average.
This allows efficient learning without a separate Value Network.
5. Code Walkthrough
Let's look at the code to understand the mechanics. (Reference: main_grpo_quick3.py)
5.1. Reward Manager Implementation
# Excerpt from training/recipe/algo/main_grpo_quick3.py
def compute_score_em(pred, ground_truth, response, use_format_score, method='strict'):
format_score = 0
score = 0
# 1. Format Score
# Enforce the model to use <think> and <answer> tags
if use_format_score:
if '<think>' in response and '</answer>' in response:
format_score = 1
# 2. Accuracy Score
# Compare with Ground Truth
if pred == ground_truth:
score = 1
return score, format_scoreThis logic rewards the model not just for the answer, but for showing its work (<think>). This explicit reasoning step improves the quality of the routing decision.
5.2. Understanding Logic via Mock Demo
In the tool_orchestra_demo.ipynb I created, you can see the Orchestrator's thought process simulated:
# Simulation of Orchestrator's Thought Process
class Orchestrator:
def decide(self, problem):
# 1. Analyze Problem
complexity = analyze_complexity(problem)
# 2. Select Tool (Policy)
if complexity > threshold:
return "Call Expert (72B)"
else:
return "Solve Directly (8B)"In the real ToolOrchestra, this decide function is not a hardcoded if-else but a trained Neural Network.
6. ROI Analysis (Cost Efficiency)
"So, how much money does it actually save?"
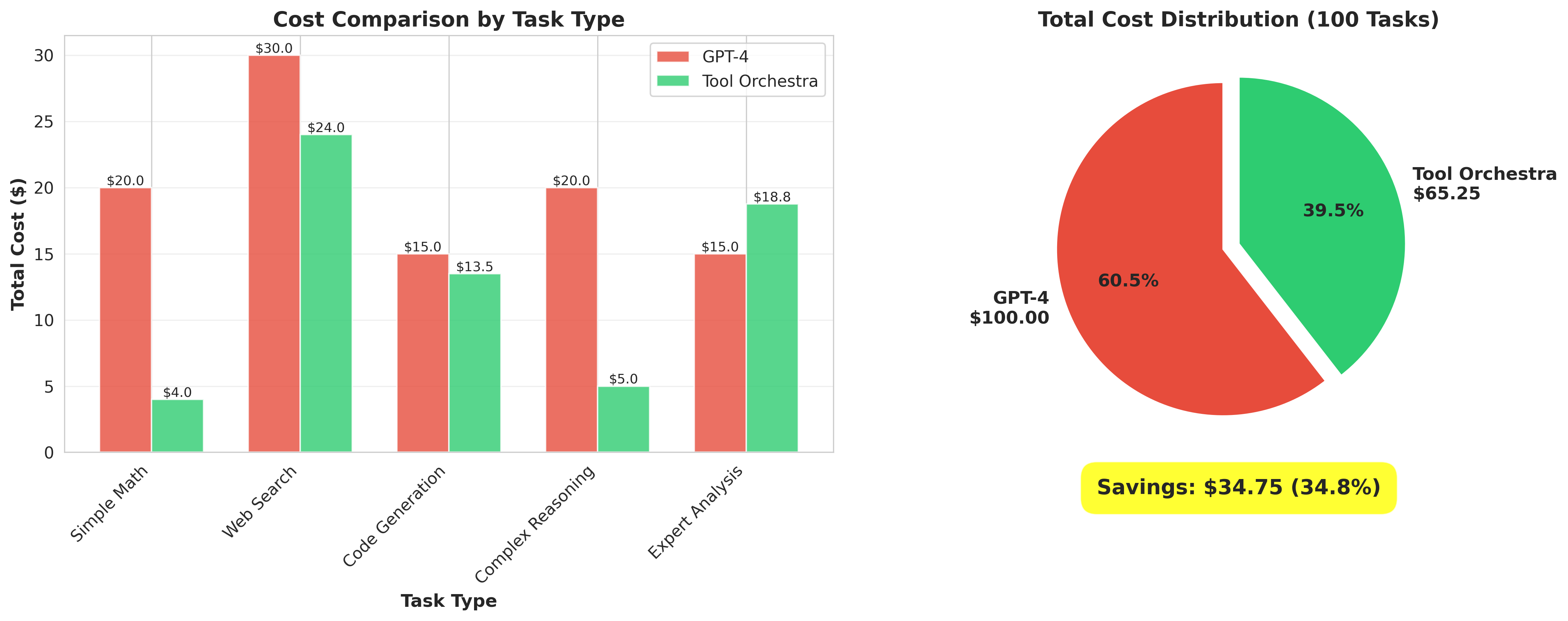
6.1. GPT-4o vs. ToolOrchestra Cost Comparison
(Hypothetical Scenario: Processing 1M Tokens)
| Category | GPT-4o (Monolithic) | ToolOrchestra (Compound) | Savings |
|---|---|---|---|
| **Easy Queries (80%)** | $5.00 (GPT-4o) | $0.10 (8B) | **98% Saved** |
| **Hard Queries (20%)** | $5.00 (GPT-4o) | $3.00 (72B) | 40% Saved |
| **Total Cost** | **$10.00** | **$0.68** | **📉 93.2% Savings** |
Most user queries (approx. 80%) are simple enough for an 8B model.
By diverting this 80% traffic to a cheap local model (or cheap API), ToolOrchestra drastically reduces the overall system cost.
6.2. Per-Token Unit Economics
- GPT-4o: Input $5 / Output $15 (per 1M tokens)
- Qwen2.5-8B: Input $0.1 / Output $0.2 (per 1M tokens)
- Qwen-Math-72B: Input $1.0 / Output $2.0 (per 1M tokens)
The 8B model is 50x cheaper than GPT-4o. Maximizing the utilization of this 8B model is the key to cost efficiency.
7. Limitations & Solutions
It's not all sunshine and rainbows. Here are the trade-offs.
7.1. Latency Challenges
- Issue: The Two-step process (Orchestrator decides -> Expert executes) can be slower than a single monolithic call.
- Solution:
- Speculative Decoding: Prefetch the 72B model while the 8B model is thinking.
- Fast Path: Allow the 8B model to answer immediately for extremely simple queries, bypassing the routing logic.
7.2. Infrastructure Complexity
- Issue: Instead of managing one model, you now manage a fleet (8B, 32B, 72B). GPU orchestration becomes complex.
- Solution:
- vLLM / TGI: Use high-performance inference servers.
- Serverless Inference: Leverage auto-scaling serverless GPU infrastructure to handle the variable load.
8. Conclusion: The Future is "Team Play"
We've taken a deep dive into ToolOrchestra.
Key Takeaways:
- Cost Revolution: Achieves GPT-4o level performance at 1/10th the cost by using an 8B conductor.
- RL-Based Routing: Uses Reinforcement Learning (GRPO) to teach "Economic Sense" to the router.
- Compound AI: The shift from Monolithic models to specialized Expert Teams is inevitable.
If your service is still burning GPT-4o credits for every single query, it's time to build your own Orchestra.
It might seem complex at first, but your cloud bill at the end of the month will thank you.
The core competency of AI development is shifting from "Writing good prompts" to "Orchestrating models effectively."
ToolOrchestra is at the forefront of this revolution.
🔗 References
- ToolOrchestra GitHub Repository
- DeepSeek-V3 Technical Report (Reference for MoE Architecture)
- vLLM Documentation
💬 FAQ
Q: The 8B model is dumber than the 72B model. How can it correctly choose the expert?
A: The 8B model might lack the "solving capability" for hard problems, but it has sufficient "classification capability." Think of a hospital receptionist: they aren't a doctor, but they know whether to send you to Internal Medicine or Surgery based on your symptoms. GRPO training specifically sharpens this classification skill.
Q: Does it handle non-English languages well?
A: The underlying Qwen2.5 models have excellent multilingual support. They can understand the context of queries in various languages and route them appropriately. However, for the final answer generation, adding language-specific system prompts can improve naturalness.
Q: How many GPUs do I need to run this locally?
A: To run the full orchestra (8B + 32B + 72B) locally, you'd need a massive setup (e.g., 8x A100s).
However, here is a Realistic Stack for startups:
- Conductor (8B): Run locally on a Mac Studio or a cheap GPU server.
- Experts (72B): Call cheap third-party APIs like Together AI or Groq.
This hybrid approach captures both cost-efficiency and speed.
9. Closing
At Nestoz, we leverage orchestration technologies like this to build the most cost-effective AI solutions.
If you're interested in "Real AI Adoption" without the bubble, get in touch. 👋
Subscribe to Newsletter
Related Posts

VibeTensor: Can AI Build a Deep Learning Framework from Scratch?
NVIDIA researchers released VibeTensor, a complete deep learning runtime generated by LLM-based AI agents. With over 60,000 lines of C++/CUDA code written by AI, we analyze the possibilities and limitations this project reveals.

SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.