Models & Algorithms
27 posts in this category
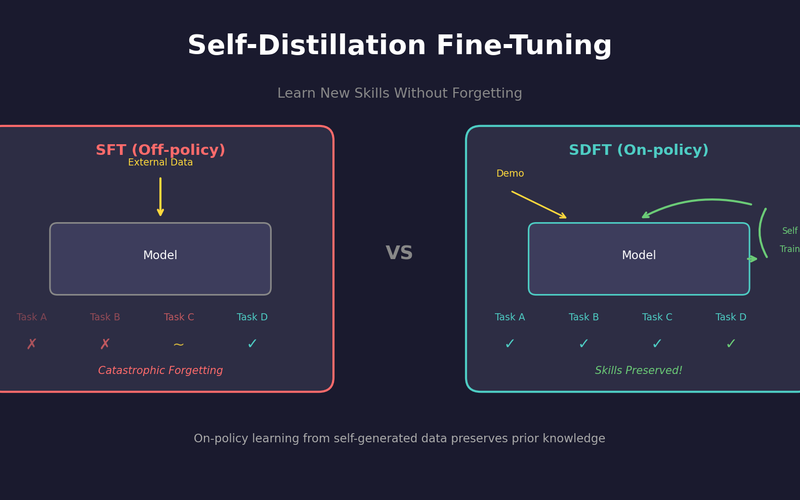
SDFT: 자기 증류로 망각 없이 학습하기
복잡한 강화학습 없이, 모델이 스스로를 선생님 삼아 새로운 기술을 배우면서도 기존 능력을 유지하는 방법.
Qwen3-Max-Thinking 스냅샷 공개: 추론형 AI의 새로운 기준
최근 LLM 시장의 트렌드는 단순히 '더 많은 데이터'를 학습하는 것을 넘어, 모델이 '어떻게 생각하느냐'에 집중하고 있습니다. 알리바바 클라우드(Alibaba Cloud)가 자사의 가장 강력한 모델 Qwen3-Max-Thinking의 API 스냅샷(qwen3-max-2026-01-23)을 공개했습니다.

YOLO26: Upgrade or Hype? 완벽 가이드
2026년 1월 출시된 YOLO26의 핵심 기능, YOLO11과의 성능 비교, 그리고 실제 업그레이드 가치가 있는지 실습과 함께 분석합니다.

RAG Evaluation: Precision/Recall을 넘어서
"RAG가 잘 동작하는지 어떻게 알죠?" — Precision/Recall만으로는 부족합니다. Faithfulness, Relevance, Context Recall까지 측정해야 진짜 품질이 보입니다.

Retrieval Planning: ReAct vs Self-Ask vs Plan-and-Solve
Query Planning 실패를 진단했다면, 이제 해결할 차례입니다. 세 가지 패턴이 각각 어떤 상황에서 빛나는지 비교합니다.

Multi-hop RAG에서 Query Planning이 실패하는 패턴과 해결책
Query Decomposition을 붙였는데 왜 여전히 틀릴까요? 분해는 시작일 뿐, 진짜 문제는 Sequencing과 Grounding에서 터집니다.

Multi-hop RAG: Temporal RAG 이후에도 계속 틀리는 이유
Temporal RAG를 붙였는데도 'who is my boss's boss?' 라는 질문에는 여전히 틀린 답을 내놓습니다. RAG는 시간을 알게 되었지만, 여전히 '다음으로 무엇을 찾아야 할지'는 모릅니다.

GraphRAG: Microsoft의 글로벌-로컬 이중 검색 전략
왜 기존 RAG는 "이 문서들의 주요 테마가 뭐야?"라는 질문에 답하지 못할까? Microsoft Research의 GraphRAG가 제시하는 커뮤니티 기반 검색의 비밀.

CFG-free Distillation: Guidance 없이 빠른 생성
Classifier-Free Guidance의 2배 연산 비용 제거. 단일 forward pass로 동일 품질 달성.

Consistency Models: 1-Step 생성을 위한 새로운 패러다임
Diffusion의 반복 샘플링 없이 단 한 번에 생성. Self-consistency property를 활용한 OpenAI의 혁신적 접근법.

SDE vs ODE: Score-based Diffusion의 수학적 기초
확률적(Stochastic) vs 결정적(Deterministic). DDPM과 DDIM의 이론적 기반인 Score-based SDE와 Probability Flow ODE를 깊이 파헤칩니다.

Stable Diffusion 3 & FLUX: MMDiT 아키텍처 완전 분석
U-Net을 버리고 Transformer로. Text와 Image를 동등하게 처리하는 MMDiT 아키텍처와 Rectified Flow, Guidance Distillation까지.

Rectified Flow: 1-Step 생성을 향한 경로 직선화
Flow Matching도 느리다면? Reflow로 경로를 펴서 1-step 생성까지. Stable Diffusion 3와 FLUX의 핵심 기술.

Flow Matching vs DDPM: 왜 ODE가 더 빠르고 직관적인가
DDPM은 1000스텝, Flow Matching은 10스텝. SDE의 곡선 경로 vs ODE의 직선 경로. 수식과 코드로 증명하는 Flow Matching의 효율성.
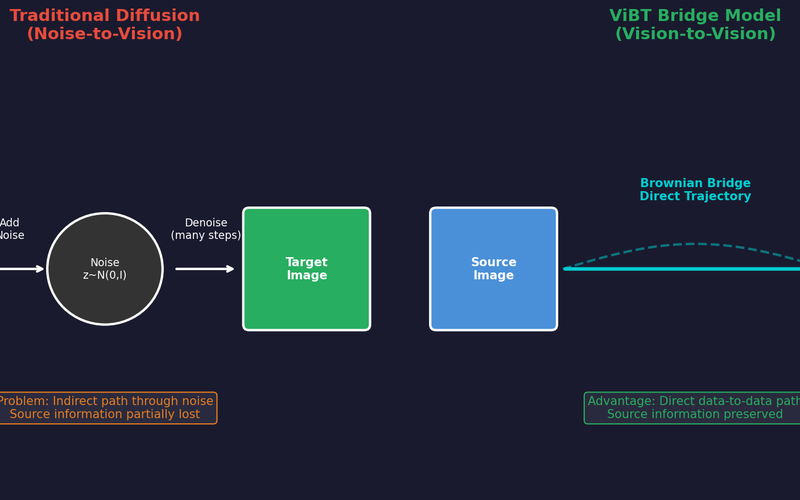
ViBT: 노이즈 없는 생성의 시작, Vision Bridge Transformer (논문 리뷰)
Brownian Bridge를 활용한 Vision-to-Vision 패러다임으로 노이즈 없이 이미지/비디오를 변환하는 ViBT의 핵심 기술과 성능을 분석합니다.
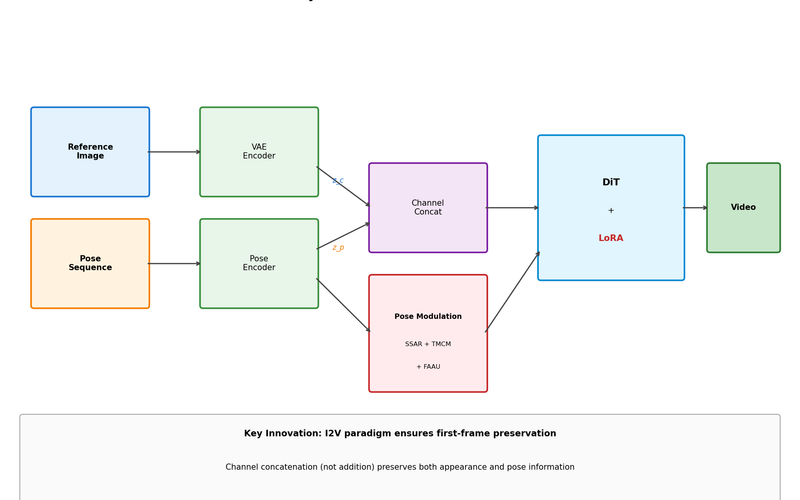
SteadyDancer 완전 분석: 첫 프레임을 지키는 인간 이미지 애니메이션의 새로운 패러다임
사진 한 장으로 춤추는 영상 만들기 - 기존 방법들이 실패한 이유와 SteadyDancer가 I2V 패러다임으로 첫 프레임 보존을 보장하며 Identity 문제를 해결한 방법을 상세히 분석합니다.
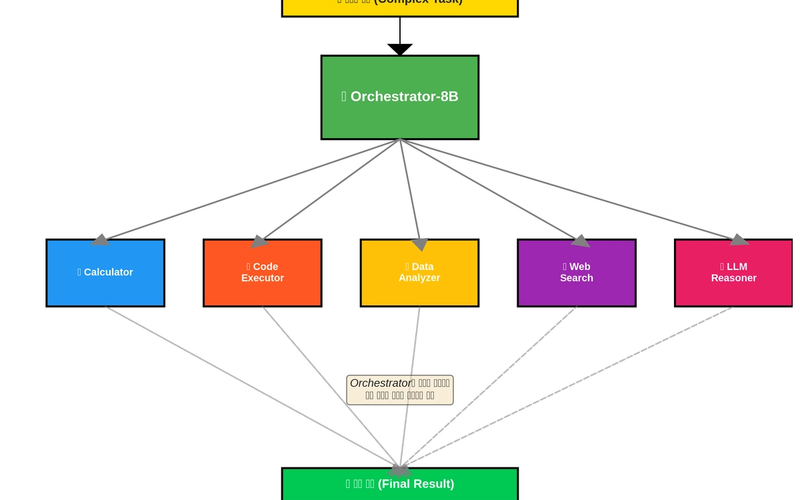
아직도 모든 질문에 GPT-4o 부르시나요? (비용 90% 아끼는 AI 오케스트라 구축법)
8B 모델이 지휘자가 되어 문제 난이도에 따라 적절한 전문가 모델을 호출하는 ToolOrchestra. GPT-4o 대비 비용은 1/10, 성능은 동등 이상인 Compound AI 시스템을 구축하는 방법을 소개합니다.

SANA: O(n²)→O(n) Linear Attention으로 1024² 이미지 0.6초 생성
Self-Attention의 quadratic 복잡도 문제를 Linear Attention이 어떻게 해결했는지. DiT 대비 100배 빠른 생성의 비밀.

PixArt-α: Stable Diffusion 학습비용 $600K를 $26K로 줄인 방법
분해 학습(Decomposed Training)으로 T2I 학습 효율을 23배 높인 비결. 학술 연구자도 접근 가능한 Text-to-Image 모델 만들기.

DiT: U-Net 버리고 Transformer 쓰니까 Scaling Law가 적용됐다 (Sora 기반기술)
U-Net은 크기 키워도 성능 향상이 수확체감. DiT는 모델이 클수록 일관되게 좋아집니다. Sora의 기반이 된 아키텍처 완전 분석.

512×512에서 1024×1024로: Latent Diffusion이 해상도 한계를 깬 방법
픽셀 공간 diffusion의 메모리 폭발 문제를 Latent Space가 어떻게 해결했는지. VAE 압축부터 Stable Diffusion 구조까지 완전 분석.

DDIM으로 Diffusion 20배 빠르게: 품질 손실 없이 1000→50 스텝
DDPM pretrained 모델 그대로 쓰면서 샘플링만 20배 빠르게. 확률적→결정론적 변환의 수학적 원리와 eta 파라미터 튜닝 가이드.

DDPM 수식 완전 정복: Forward/Reverse Process 직접 유도하기
GAN의 mode collapse 없이 안정적으로 고품질 이미지를 생성하는 DDPM. β schedule부터 loss 함수까지 수식을 하나씩 유도하며 이해합니다.

긴 문장 번역이 망가지는 이유: Context Vector 병목 현상 완전 분석
문장이 40단어만 넘어도 BLEU가 절반으로 떨어지는 현상. 정보 이론과 gradient flow 관점에서 원인을 파헤치고 Attention이 필요한 이유를 증명합니다.

Attention 구현할 때 Bahdanau vs Luong, 뭘 써야 하나? (결론: Luong)
additive vs multiplicative 방식의 성능/속도 차이를 실험으로 비교. 실무에서는 왜 Luong을 더 많이 쓰는지 코드로 확인합니다.

직접 구현하며 이해하는 Seq2Seq: 가변 길이 입출력 문제를 해결한 첫 번째 방법
고정 크기 입출력만 가능했던 신경망의 한계를 Encoder-Decoder가 어떻게 해결했는지, 수학적 원리부터 PyTorch 구현까지.

AdamW vs Lion: GPU 메모리 33% 절약하면서 성능은 유지하는 방법
Lion optimizer가 AdamW보다 메모리를 33% 아끼는 원리와 실제 적용 시 주의해야 할 하이퍼파라미터 튜닝 가이드. 잘못 쓰면 오히려 손해입니다.