SteadyDancer Complete Analysis: A New Paradigm for Human Image Animation with First-Frame Preservation
Make a photo dance - why existing methods fail and how SteadyDancer solves the identity problem by guaranteeing first-frame preservation through the I2V paradigm.
Introduction: Why This Paper Matters
"Take this photo and make it dance."
Until 2024, this request would have seemed like something straight out of a science fiction movie. But with the emergence of Stable Diffusion, DALL-E, and Midjourney, generative AI has exploded in capability, and now animating still images has become reality.
However, there's a problem. Existing methods fail to preserve "the image you provided". When your input photo becomes a video, the face might change, the clothes might differ, or the person might look completely different.
SteadyDancer addresses this problem head-on. By introducing the concept of "First-Frame Preservation", it guarantees that your input image is used exactly as-is as the first frame of the video.
In this article, we'll deeply analyze the technical innovations of SteadyDancer, examine why existing methods fail, and explore how SteadyDancer solves these problems.
1. Background: History and Challenges of Human Image Animation
1.1 What is Image Animation?
Image Animation is the technology of generating moving video from a still image. Human Image Animation specifically aims to take a photo of a person and create video of that person performing specific actions.
1.2 History of Technical Development
Early Era: GAN-Based Warping (2019-2021)
Early research combined GAN (Generative Adversarial Networks) with image warping techniques.
Representative Works:
- First Order Motion Model (FOMM, NeurIPS 2019): Keypoint-based motion estimation
- Liquid Warping GAN (ICCV 2019): Warping using 3D body mesh
- MRAA (CVPR 2021): Articulated motion representation
Limitations:
- Distortion with large motions
- Difficulty separating background and person
- Resolution constraints (typically 256x256)
Middle Era: Diffusion-Based Methods (2022-2023)
The emergence of Diffusion models dramatically improved generation quality.
Representative Works:
- DisCo (CVPR 2023): First diffusion-based human animation
- Animate Anyone (2023): Introduced ReferenceNet for better identity preservation
- MagicAnimate (2023): Added temporal consistency modules
- CHAMP (2024): Utilized 3D guidance
Limitations:
- Scalability limits of UNet architecture
- Quality degradation in long video generation
- Persistent identity drift issues
Current Era: DiT-Based Methods (2024-2025)
With OpenAI Sora's emergence, DiT (Diffusion Transformer) architecture gained attention.
Representative Works:
- Wan 2.1: Powerful base I2V model
- RealisDance-DiT: DiT-based dance generation
- HyperMotion: Hypernetwork-based control
- SteadyDancer (this paper): I2V-based first-frame preservation
1.3 Why is Human Image Animation Difficult?
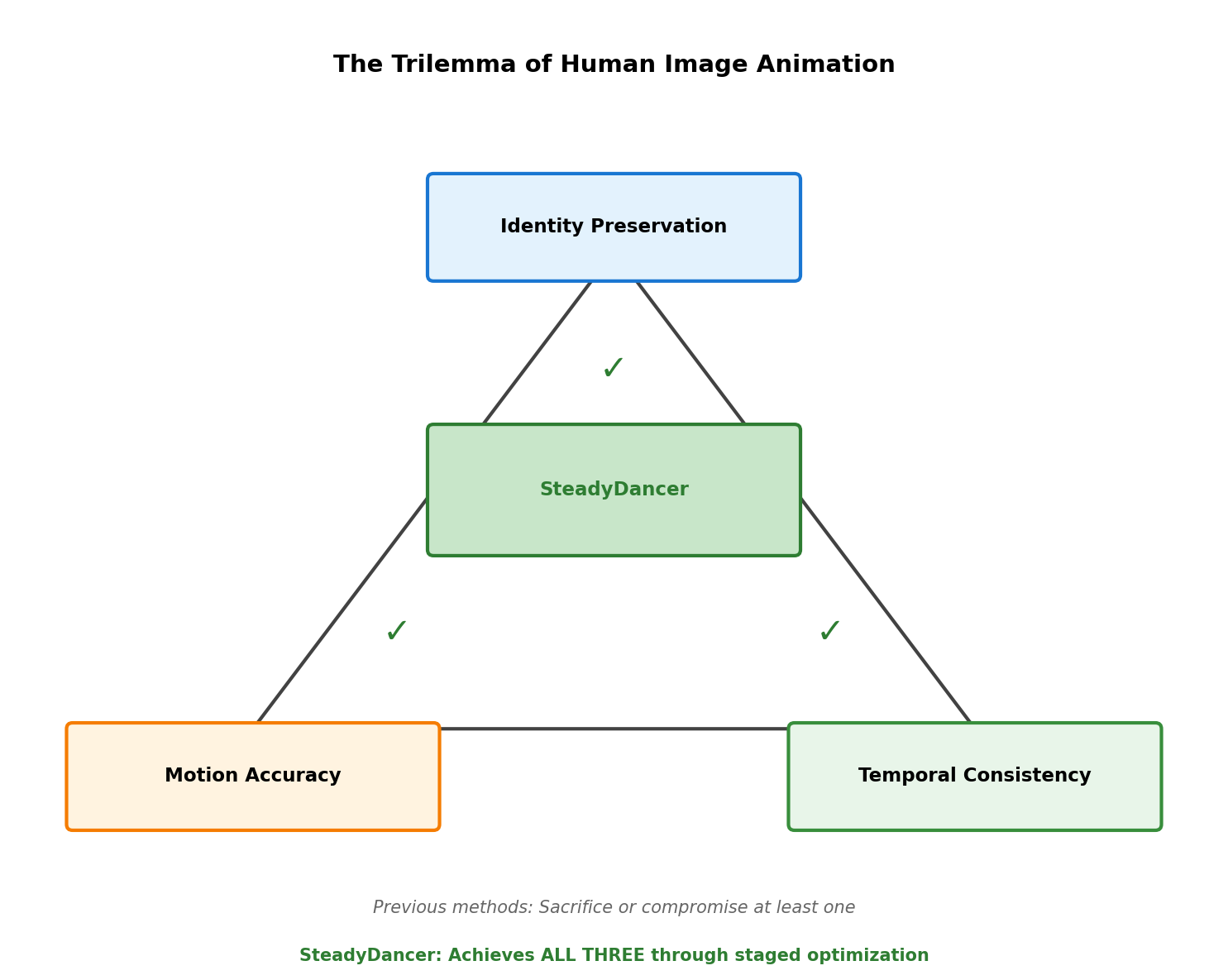
Human image animation faces these inherent challenges:
1) Identity Preservation
- The person in the generated video must look identical to the original image
- Must maintain all characteristics: face, body type, skin tone, clothing
2) Motion Accuracy
- Must accurately follow the driving pose sequence
- From fine finger movements to full-body actions
3) Temporal Consistency
- No flickering between frames
- Consistent clothing, background throughout
4) Physical Plausibility
- Clothes must move naturally
- Hair and accessory dynamics must be realistic
2. Problem Definition: Why Do Existing Methods Fail?
2.1 The Dominance of Reference-to-Video (R2V) Paradigm
Most human image animation methods to date follow the Reference-to-Video (R2V) paradigm.
How R2V Works:
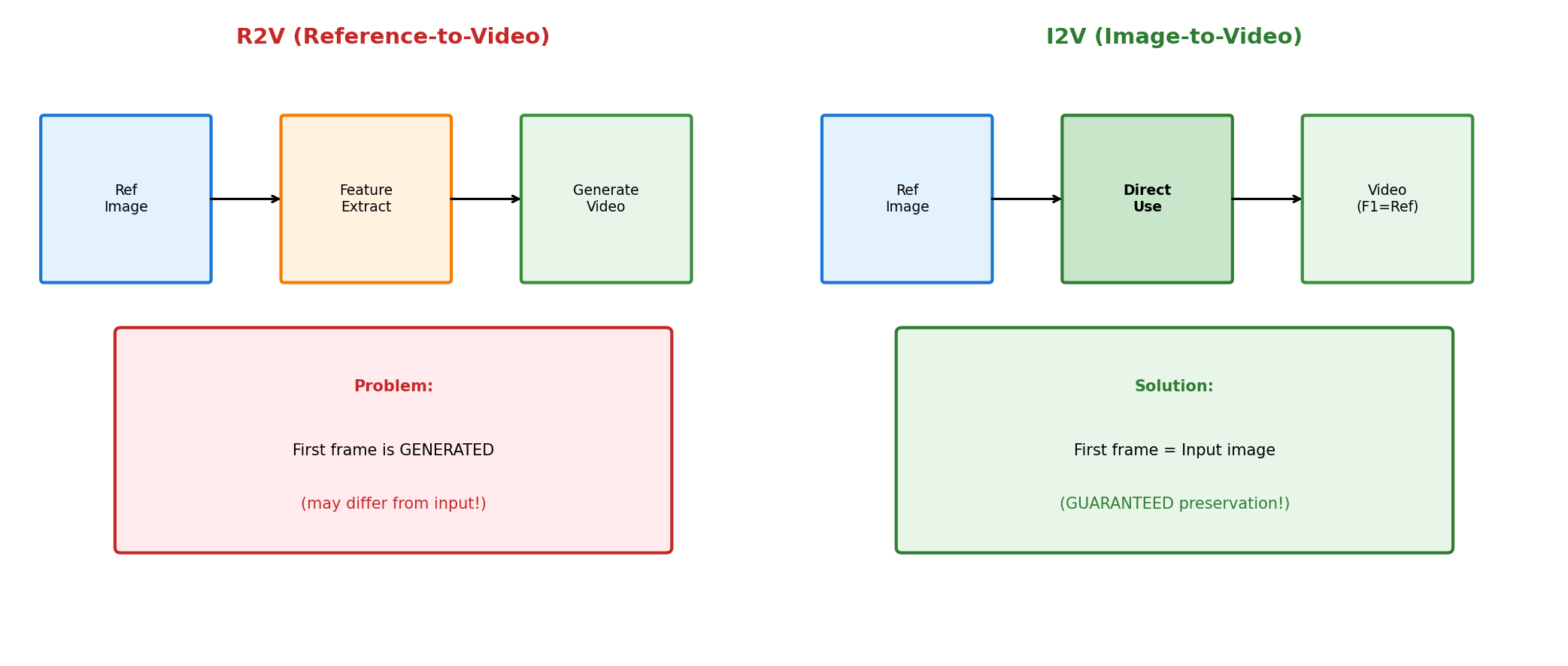
Representative R2V Models:
- Animate Anyone
- MagicAnimate
- CHAMP
- HumanVid
- RealisDance
2.2 The Fundamental Problem of R2V: Spatio-Temporal Misalignment
R2V methods "extract features from the reference image to generate new video." The reference image is not directly used as the first frame.
Why is this a problem? In real-world usage, two types of misalignment occur:
2.2.1 Spatial Misalignment
When the reference image person and driving poses have different body structures:
Causes:
- Different camera angles between reference image and driving video
- Body type differences (slim vs. muscular)
- Clothing differences (short sleeves vs. long sleeves)
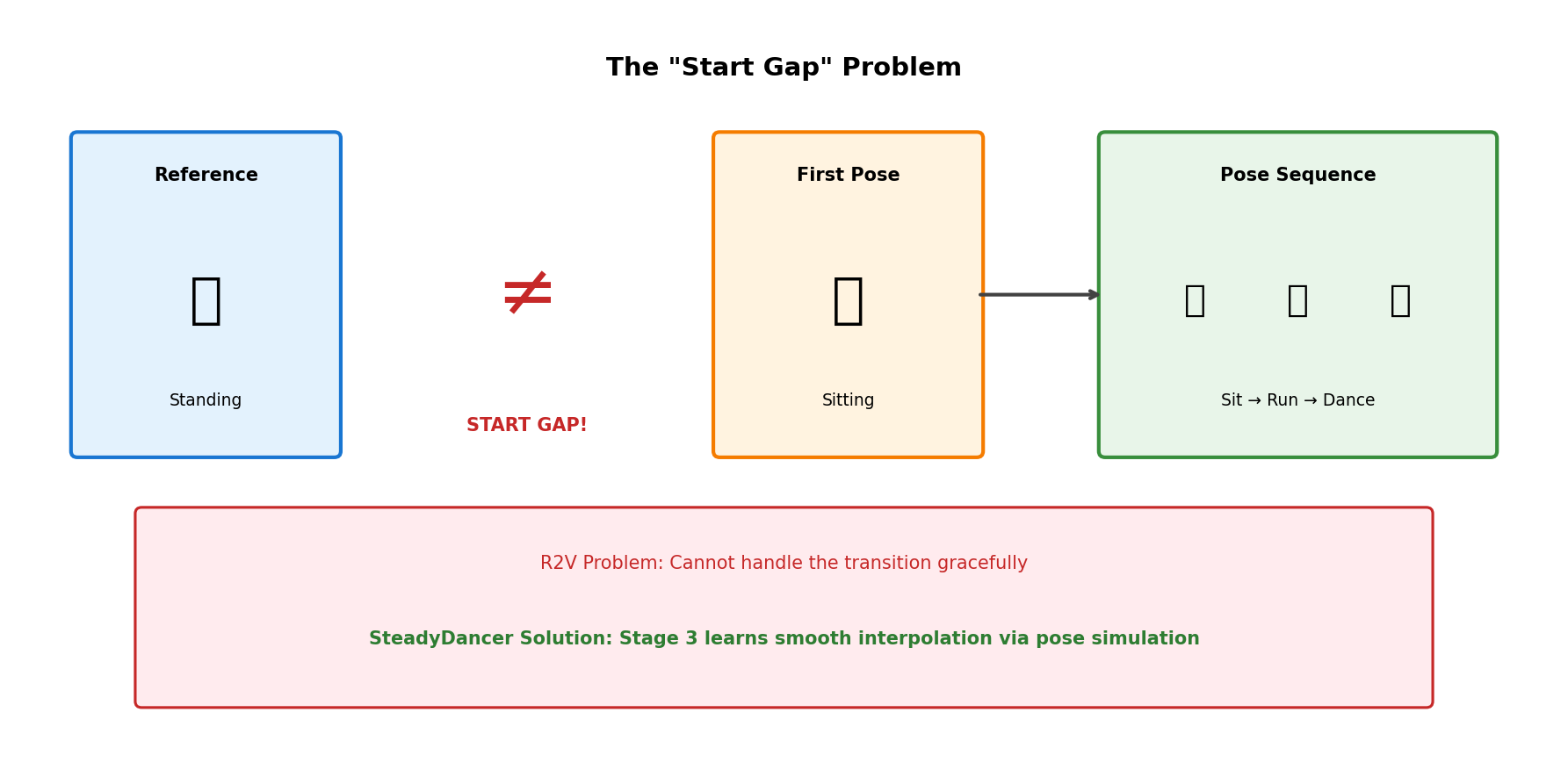
2.2.2 Temporal Misalignment - "Start Gap"
When the reference image pose and the first pose of the sequence differ:
Real-World Scenarios:
- User inputs frontal photo, but driving video starts from side view
- Arms down in photo, but driving video starts with arms raised
- Standing in photo, but driving video starts sitting
2.3 Why Don't Existing Benchmarks Catch This?
The fatal design flaw of existing benchmarks (TikTok, RealisDance):
Consequences:
- R2V methods show good performance on existing benchmarks
- But fail in real-world usage (different source image-video pairs)
- Benchmark performance ≠ Real-world performance
🎬 X-Dance Benchmark Demos
Below are demo videos from the official SteadyDancer project page:
🎬 RealisDance Benchmark Demos
Below are demo videos from the official SteadyDancer project page:
2.4 The "Dual Failure" of R2V
When spatio-temporal misalignment exists, R2V methods fail at both objectives:
1) Identity Preservation Failure:
- Generates appearance different from reference image
- Face looks different
- Changes in clothing, body type
2) Motion Control Failure:
- Cannot accurately follow driving poses
- Awkward jumps at the start
- Pose deviation during video
3. SteadyDancer's Core Idea: A Paradigm Shift
3.1 Shifting to Image-to-Video (I2V) Paradigm
The core insight of SteadyDancer:
"First-frame preservation must be a 'guarantee', not a 'hope'."
To achieve this, they adopt I2V (Image-to-Video) paradigm instead of R2V.
How I2V Works:
3.2 R2V vs I2V Comparison
| Aspect | R2V (Reference-to-Video) | I2V (Image-to-Video) |
|---|---|---|
| **First Frame** | Newly generated | Input image as-is |
| **Identity Preservation** | Depends on feature extraction (imperfect) | Structurally guaranteed |
| **Start Gap Handling** | Ignored or incomplete | Natural transition generated |
| **Control Complexity** | Relatively simple | Requires additional design |
| **Representative Models** | Animate Anyone, CHAMP | Wan 2.1, SteadyDancer |
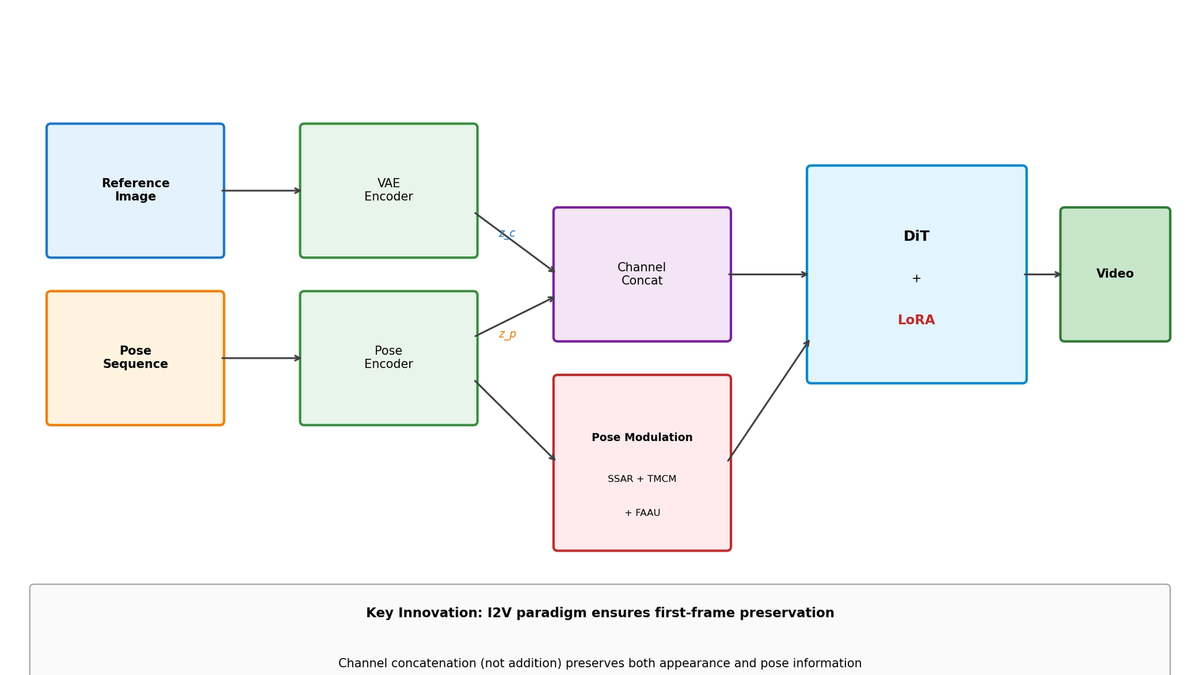
3.3 The Challenge of I2V: Adding Pose Control
I2V guarantees first-frame preservation, but how to add pose control becomes the new challenge.
Naive Approaches:
# Method 1: Simple addition
z_t = ChannelConcat(ẑ_t, m, z_c + z_p)
# Method 2: Adapter-based
z_t = ChannelConcat(ẑ_t, m, z_c)
z_t = z_t + Adapter(z_p)Problems:
- Addition: Static appearance info (z_c) and dynamic pose info (z_p) get mixed, losing both
- Adapter: High parameter count, may damage base model's knowledge
3.4 SteadyDancer's Three Core Innovations
SteadyDancer solves these problems with three technologies:
4. Technical Deep Dive (1): Condition-Reconciliation Mechanism
4.1 The Problem: Two Conflicting Conditions
When adding pose control to I2V models, two conditions conflict:
1) Appearance Condition - z_c:
- Extracted from reference image
- Static information: face, clothing, background
- "How it should look"
2) Pose Condition - z_p:
- Extracted from driving pose sequence
- Dynamic information: body position, joint angles
- "How it should move"
4.2 Solution: Three Levels of Reconciliation
SteadyDancer reconciles conditions at three levels:
4.2.1 Condition Fusion Level
Existing Approach (Addition):
z_input = ChannelConcat(ẑ_t, m, z_c + z_p)- Two signals mix and become indistinguishable
- Information loss occurs
SteadyDancer (Channel Concatenation):
z_input = ChannelConcat(ẑ_t, m, z_c, z_p)- Each condition maintains independent channels
- Model learns how to combine them
4.2.2 Condition Injection Level
Existing Approach (Adapter):
- Add separate adapter network
- Increases parameter count (tens to hundreds of M)
- May damage base model knowledge
SteadyDancer (LoRA):
- Uses Low-Rank Adaptation
- Minimal parameter addition (~few M)
- Preserves base model knowledge
4.2.3 Condition Augmentation Level
Purpose: Strengthen connection between first frame and pose condition
Methods:
- Temporal Connection: Add first frame's pose latent to pose sequence
- CLIP Feature Augmentation: Include first frame's pose features in CLIP embedding
# Temporal connection
z_p_augmented = TemporalConcat(z_p_first_frame, z_p_sequence)
# CLIP feature augmentation
clip_features = Concat(clip_image, clip_pose_first_frame)4.3 Overall Architecture
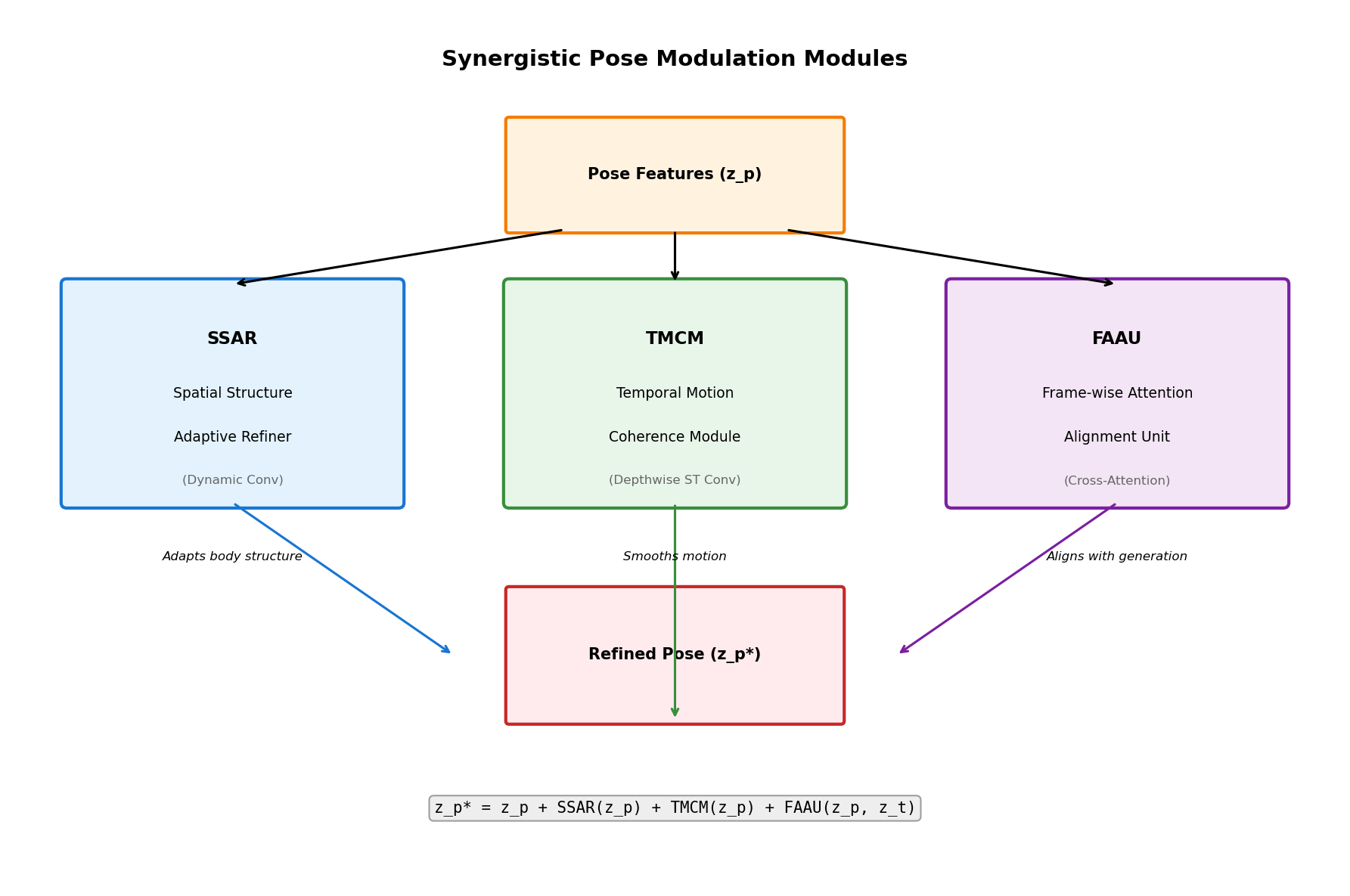
5. Technical Deep Dive (2): Synergistic Pose Modulation Modules
5.1 The Problem: Simple Condition Fusion Isn't Enough
The condition-reconciliation mechanism alone cannot fully solve the spatio-temporal misalignment problem.
Why?
- Pose features (z_p) may not be compatible with reference image's feature space
- Adaptation needed due to body structure differences
- Must ensure motion continuity between frames
5.2 Three Synergistic Modules
SteadyDancer designs three specialized modules to solve these problems:
5.3 SSAR: Spatial Structure Adaptive Refiner
Role: Resolve spatial structure mismatch
Problem Scenario:
- Reference image: arm length 60cm
- Driving pose: extracted based on 70cm arm length
- Result: Direct pose application causes stretching or awkwardness
Solution: Dynamic Convolution
Advantages of Dynamic Convolution:
- Adaptive transformation, not fixed
- Flexibly handles various body type differences
- Learnable transformation for optimization
5.4 TMCM: Temporal Motion Coherence Module
Role: Resolve temporal motion discontinuity
Problem Scenario:
- Frame 1: Right arm raised 30°
- Frame 2: Right arm raised 45°
- Frame 3: Right arm raised 90° (sudden change!)
- Result: Motion feels choppy or jumpy
Solution: Depthwise Spatio-Temporal Convolution
Why Depthwise Convolution?
- Channel-wise independent processing for efficiency
- Separates spatial/temporal feature learning
- Minimizes parameter count
5.5 FAAU: Frame-wise Attention Alignment Unit
Role: Precise frame-by-frame alignment
Problem Scenario:
- Poses preprocessed by SSAR and TMCM exist
- But need alignment with current state of denoising process
- Each frame may need different degrees of alignment
Solution: Cross-Attention
5.6 Synergy of the Three Modules
The three modules cooperate to solve different levels of problems:
6. Technical Deep Dive (3): Staged Decoupled-Objective Training
6.1 The Problem: Difficulty of Simultaneous Optimization
Optimizing multiple objectives simultaneously causes problems:
Objectives to Optimize:
- Motion Fidelity: Must accurately follow poses
- Visual Quality: Maintain base model's generation quality
- Temporal Coherence: No flickering between frames
- Motion Continuity: Handle Start Gap
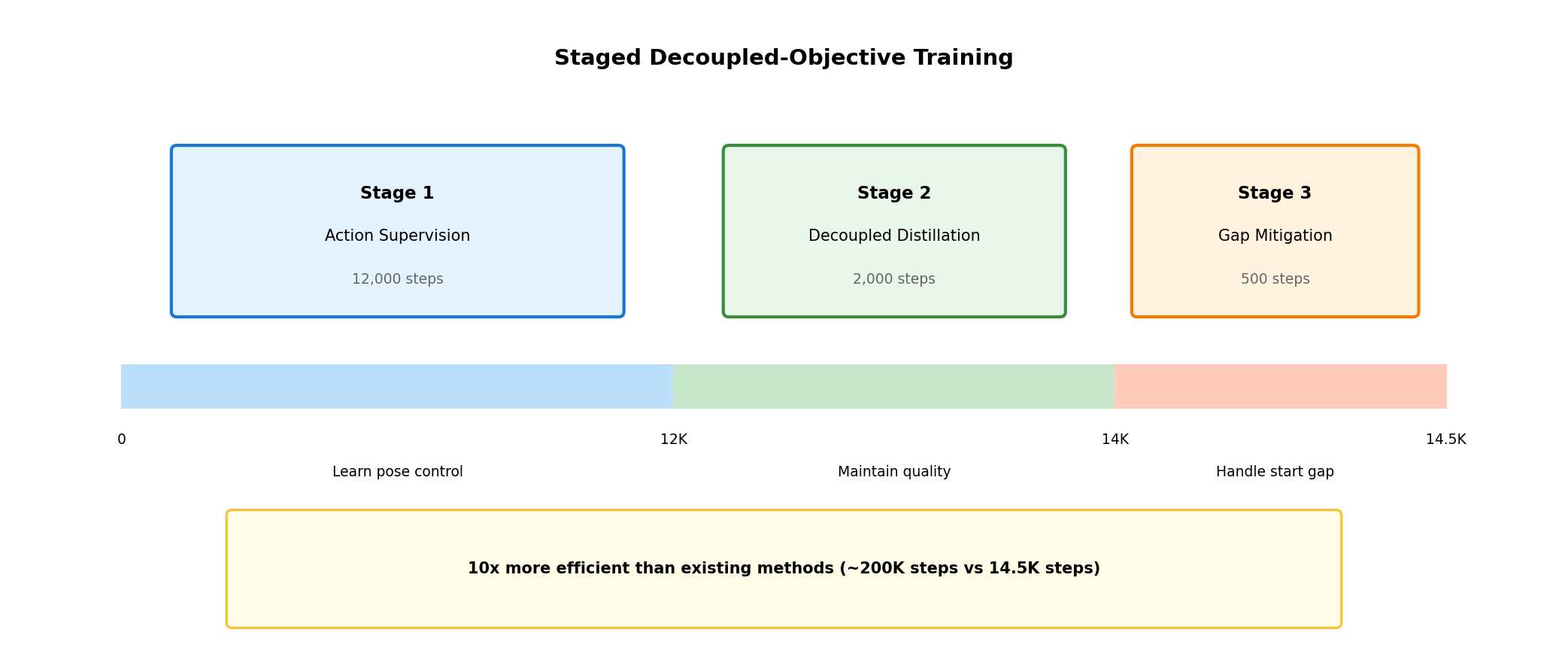
6.2 Solution: Staged Decoupled Training
SteadyDancer divides training into three stages:
6.3 Stage 1: Action Supervision
Purpose: Quickly acquire pose control ability
Duration: 12,000 steps
Method:
- Use standard diffusion loss
- Fine-tune only LoRA (freeze original weights)
- Learn pose condition → motion generation mapping
# Stage 1 Loss
L_action = E[||v_θ(z_t, t, c, p) - v_target||²]
# where:
# v_θ: model prediction
# z_t: noised latent vector
# t: timestep
# c: image condition
# p: pose condition
# v_target: target velocityResult:
- Basic pose following capability
- But visual quality may be lower than base model
6.4 Stage 2: Condition-Decoupled Distillation
Purpose: Maintain base model's visual quality
Duration: 2,000 steps
Problem: Training collapse with standard distillation
Formulation:
# Velocity decomposition
v_θ = v_uncond + v_cond
# Stage 2 Loss
L_distill = L_uncond + L_cond
# Unconditional component: Teacher distillation
L_uncond = E[||v_uncond - v_teacher_uncond||²]
# Conditional component: Maintain original supervision
L_cond = E[||v_cond - (v_target - v_teacher_uncond)||²]Key Insight:
- Only distill unconditional component from Teacher
- Conditional component (pose control) trained with original method
- Two objectives don't interfere with each other
6.5 Stage 3: Motion Discontinuity Mitigation
Purpose: Solve Start Gap problem
Duration: 500 steps
Problem: Discontinuity between reference image pose and first pose
Solution: Pose Simulation
6.6 Training Efficiency
SteadyDancer Training Efficiency:
| Item | SteadyDancer | Existing (e.g., Animate Anyone) |
|---|---|---|
| Training Steps | ~14,500 | ~200,000 |
| Training Data | 7,338 clips (10.2 hours) | 1M+ videos |
| GPU | 8x H800 | 32x A100 (estimated) |
| Relative Cost | 1x | ~10-50x |
Why So Efficient?
- LoRA-based: Train only part of model, not entire thing
- Staged learning: Focused optimization at each stage
- Leverage powerful base model: Maximum use of Wan 2.1's prior knowledge
- Efficient data utilization: Learn core capabilities with less data
7. Experimental Results Analysis: Quantitative Comparisons
7.1 Compared Models
UNet-based (Previous Generation):
- Animate Anyone (2023)
- MagicAnimate (2023)
- CHAMP (2024)
- HumanVid (2024)
DiT-based (Current Generation):
- RealisDance-DiT (2024)
- Wan-Animate (2024)
- UniAnimate-DiT (2024)
- HyperMotion (2024)
7.2 TikTok Dataset Results
Setup:
- Reference image and pose extracted from same video
- Low-level metrics: SSIM, PSNR, LPIPS, FID, FVD
Analysis:
- SteadyDancer achieves best performance on all metrics
- Particularly large improvement in FVD (Fréchet Video Distance)
- Overall performance boost confirmed from UNet → DiT transition
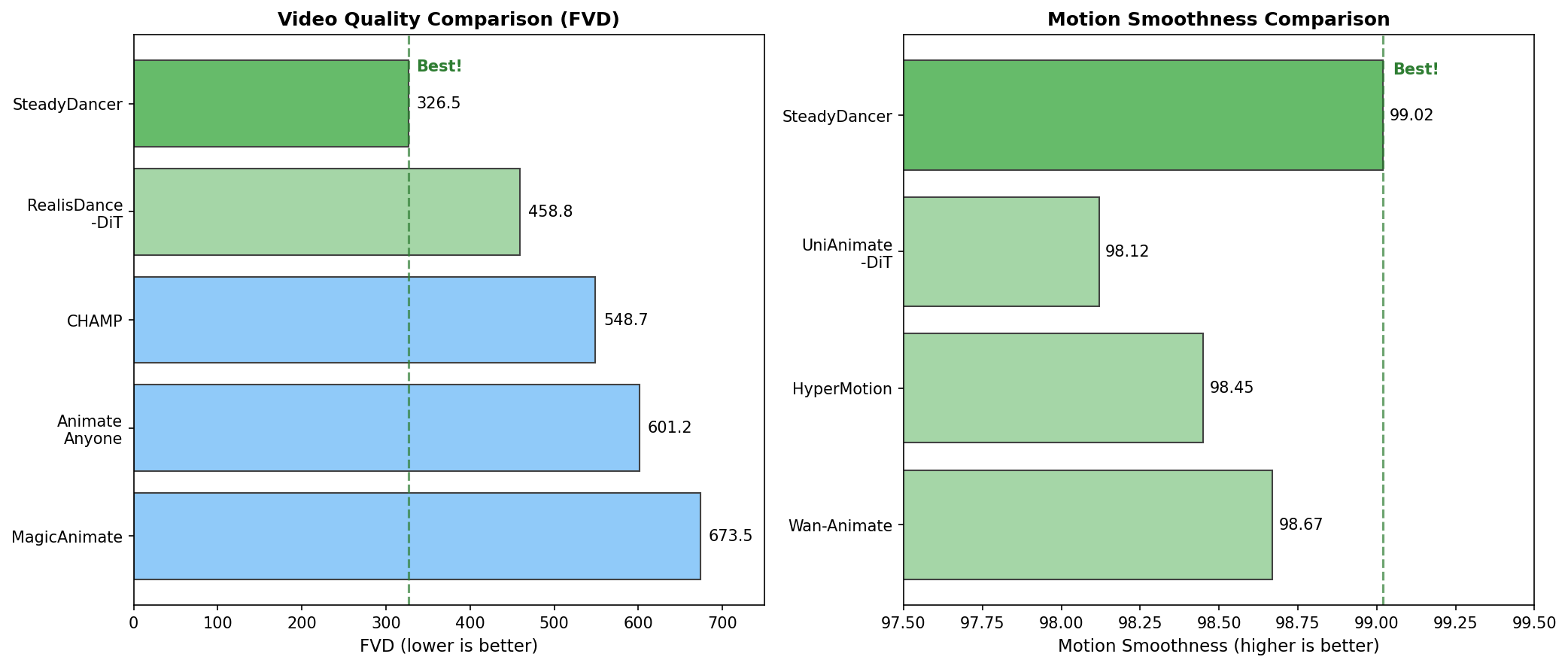
7.3 RealisDance-Val Results
Setup:
- Vbench-I2V high-level metrics
- Subject Consistency, Background Consistency, Motion Smoothness, etc.
Key Findings:
- Subject Consistency: Best at identity preservation (97.34)
- Motion Smoothness: 99.02, near-perfect smoothness
- FVD: 326.49, 16% improvement over second place
7.4 Why These Results?
8. X-Dance Benchmark: Testing Real-World Performance
8.1 Limitations of Existing Benchmarks
The fatal flaw of existing benchmarks like TikTok and RealisDance:
8.2 X-Dance Benchmark Design
SteadyDancer proposes the X-Dance benchmark to test truly difficult scenarios:
Core Design Principle: Different-Source
- Reference image and driving video from different sources
- Reflects real-world usage
8.3 X-Dance Results: R2V's "Catastrophic Dual Failure"
8.4 Implications of X-Dance
- Blind spot of existing benchmarks: Don't test truly difficult scenarios
- Fundamental limitation of R2V: Cannot handle spatio-temporal misalignment
- Strength of I2V: First-frame preservation solves identity problem
- Value of SteadyDancer: A solution that works in real-world conditions
9. Ablation Study: Contribution of Each Module
9.1 Condition-Reconciliation Mechanism Ablation
Experimental Setup:
- Compare condition fusion methods (addition vs concatenation)
- Compare condition injection methods (adapter vs LoRA)
- Compare with/without condition augmentation
9.2 Pose Modulation Module Ablation
Individual Contribution of Each Module:
9.3 Training Pipeline Ablation
Necessity of Each Stage:
9.4 Detailed Analysis of Stage 3 Pose Simulation
Discontinuity Mitigation Effectiveness:
10. Limitations and Future Research Directions
10.1 Current Limitations
10.1.1 Domain Gap with Stylized Images
Potential Solutions:
- Expand training data to include stylized images
- Apply domain adaptation techniques
- Add style preservation loss function
10.1.2 Extreme Motion Discontinuity
Potential Solutions:
- Expand Stage 3 training
- Intermediate pose generation
- Add physics-based constraints
10.1.3 Pose Estimation Error Accumulation
Potential Solutions:
- Improve pose estimator or use ensemble
- Add error tolerance mechanism
- Self-correction learning
10.2 Computational Cost
10.3 Future Research Directions
- Real-time Inference: Model lightweighting for speed improvement
- Style Diversity: Support for various art styles
- Long Video Generation: Extend beyond current 5-second limit
- Multiple People: Simultaneous animation of multiple persons
- 3D Consistency: Consistent generation from various viewpoints
11. Hands-On: Using SteadyDancer
11.1 Environment Setup
# 1. Create Conda environment
conda create -n steadydancer python=3.10
conda activate steadydancer
# 2. Install PyTorch (CUDA 12.1)
pip install torch==2.5.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 3. Install base dependencies
pip install -r requirements.txt
# 4. Install Flash Attention
pip install flash-attn --no-build-isolation
# 5. Install xformers
pip install xformers
# 6. Pose extraction libraries
pip install mmpose mmdet mmengine
# 7. Video processing libraries
pip install moviepy decord11.2 Model Download
# Download model from HuggingFace
# Method 1: Using huggingface-cli
pip install huggingface_hub
huggingface-cli download MCG-NJU/SteadyDancer-14B --local-dir ./models/steadydancer
# Method 2: Using Git LFS
git lfs install
git clone https://huggingface.co/MCG-NJU/SteadyDancer-14B ./models/steadydancer11.3 Pose Extraction and Alignment
# Step 1: Extract poses from driving video
python preprocess/extract_pose.py \
--video driving_video.mp4 \
--output_dir preprocess/output/poses/
# Step 2: Align poses with reference image
# Positive condition (normal alignment)
python preprocess/pose_align.py \
--image reference_image.jpg \
--pose_dir preprocess/output/poses/ \
--output_dir preprocess/output/aligned_pos/
# Negative condition (augmented alignment - optional)
python preprocess/pose_align_withdiffaug.py \
--image reference_image.jpg \
--pose_dir preprocess/output/poses/ \
--output_dir preprocess/output/aligned_neg/11.4 Generate Animation
# Basic generation (single GPU)
python generate_dancer.py \
--task i2v-14B \
--size 1024*576 \
--prompt "A person dancing gracefully with smooth movements" \
--image reference_image.jpg \
--cond_pos_folder preprocess/output/aligned_pos/ \
--output_dir outputs/
# Multi-GPU generation (FSDP + xDiT USP)
torchrun --nproc_per_node=4 generate_dancer.py \
--task i2v-14B \
--size 1024*576 \
--prompt "A person dancing gracefully with smooth movements" \
--image reference_image.jpg \
--cond_pos_folder preprocess/output/aligned_pos/ \
--output_dir outputs/ \
--use_fsdp11.5 Key Parameter Descriptions
11.6 Tips and Best Practices
11.7 ComfyUI Integration
SteadyDancer can also be used with ComfyUI:
# Install ComfyUI-WanVideoWrapper
cd ComfyUI/custom_nodes
git clone https://github.com/xxx/ComfyUI-WanVideoWrapper
cd ComfyUI-WanVideoWrapper
pip install -r requirements.txt
# Copy model files to ComfyUI model folder
cp -r /path/to/SteadyDancer-14B ComfyUI/models/steadydancer/12. Conclusion and Implications
12.1 SteadyDancer's Core Contributions
12.2 Practical Implications
For Video Producers:
- High-quality human animation becomes more accessible
- Greater freedom in reference image selection
- Integrable into VFX pipelines
For Researchers:
- Demonstrates effectiveness of I2V paradigm
- Provides solution for condition conflict problem
- Confirms validity of staged training
For Industry:
- SOTA achievable with less training cost
- Solution that works in real-world conditions
- Production-ready quality level
12.3 Remaining Challenges
- Real-time Processing: Current inference speed inadequate for real-time applications
- Style Generalization: Extension to various art styles
- Long Videos: Generation beyond 5 seconds
- Multiple People: Simultaneous animation of multiple persons
- Interactive Control: Support for real-time pose input
12.4 Closing Thoughts
SteadyDancer presents a paradigm shift in human image animation. The seemingly simple goal of "preserving the first frame" was actually a very difficult problem, requiring systematic approaches: I2V paradigm adoption, condition reconciliation mechanism, synergistic pose modules, and staged training.
Particularly noteworthy is the training efficiency. Achieving SOTA with less than 1/10 the data and training cost of existing methods demonstrates that proper design can be more effective than brute-force scaling.
The X-Dance benchmark raises the important issue that "existing benchmarks don't reflect real-world difficulties." This is expected to contribute to the research community moving toward more realistic evaluation standards.
References
- [Paper] Zhang et al., "SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation", arXiv:2511.19320, 2025
- [GitHub] https://github.com/MCG-NJU/SteadyDancer
- [Project Page] https://mcg-nju.github.io/steadydancer-web/
- [HuggingFace Model] https://huggingface.co/MCG-NJU/SteadyDancer-14B
- [X-Dance Dataset] https://huggingface.co/datasets/MCG-NJU/X-Dance
Appendix A: Glossary
| Term | Description |
|---|---|
| **R2V (Reference-to-Video)** | Paradigm that extracts features from reference image to generate new video |
| **I2V (Image-to-Video)** | Paradigm that directly uses input image as first frame |
| **Start Gap** | Discontinuity between reference image pose and first frame of pose sequence |
| **Identity Drift** | Phenomenon where original person's identity changes during generation |
| **DiT (Diffusion Transformer)** | Transformer-based Diffusion model architecture |
| **LoRA (Low-Rank Adaptation)** | Technique for efficiently fine-tuning models with low-rank matrices |
| **FVD (Fréchet Video Distance)** | Metric for measuring generated video quality |
| **CFG (Classifier-Free Guidance)** | Technique for controlling conditional generation strength |
Appendix B: Related Work
B.1 GAN-Based Methods
- FOMM (First Order Motion Model): Pioneer of keypoint-based motion estimation
- Liquid Warping GAN: Utilized 3D body mesh
- MRAA: Articulated motion representation
B.2 UNet Diffusion-Based Methods
- DisCo: First diffusion-based human animation
- Animate Anyone: Introduced ReferenceNet
- MagicAnimate: Temporal consistency module
- CHAMP: Utilized 3D guidance
B.3 DiT-Based Methods
- Wan 2.1: Powerful base I2V model
- RealisDance-DiT: DiT-based dance generation
- HyperMotion: Hypernetwork-based control
- SteadyDancer: I2V-based first-frame preservation (this paper)
Appendix C: Hardware Requirements
| Component | Minimum | Recommended |
|---|---|---|
| GPU | RTX 3090 (24GB) | A100/H100 (80GB) |
| VRAM | 24GB | 80GB+ |
| RAM | 32GB | 64GB+ |
| Storage | 100GB SSD | 500GB+ NVMe |
| CUDA | 11.8+ | 12.1+ |
Appendix D: Frequently Asked Questions (FAQ)
Q: Is real-time generation possible?
A: Not currently. Generating a 5-second video takes several minutes. Future model lightweighting research is needed.
Q: Does it work with anime characters?
A: Works with limitations. Performance may degrade for stylized images since training was primarily on realistic data.
Q: Can it animate multiple people simultaneously?
A: The current version only supports single person. Multi-person support is a future research topic.
Q: Can I use it without training?
A: Yes, pre-trained models are provided. Inference-only usage is possible.
Q: Is commercial use allowed?
A: Released under Apache-2.0 license, allowing commercial use. However, check the license of the base model (Wan 2.1) as well.
Subscribe to Newsletter
Related Posts

SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.