Why Agentic RAG? — Query Routing and Adaptive Retrieval
Diagnose naive RAG limitations, classify query intent, and route to the optimal retrieval source with LangGraph. Implement adaptive retrieval that skips unnecessary searches.

Getting Started with Agentic RAG — Query Routing and Adaptive Retrieval
RAG handles "What's the weather in Seoul?" just fine, but fails at "Analyze how Seoul's weather has changed compared to last year." Why? Because a single vector search simply cannot handle such complex, multi-faceted questions.
Traditional RAG always searches the vector DB for similar documents whenever a question comes in. But real-world questions are far more complex. Some require real-time news, others need SQL queries to extract structured data, and some are general knowledge questions that don't need retrieval at all.
Agentic RAG solves this problem. The LLM analyzes the question, autonomously determines the optimal retrieval strategy, and combines multiple sources to generate an answer. In this article, we cover the first core techniques of Agentic RAG: Query Routing and Adaptive Retrieval.
Series: Part 1 (this post) | Part 2: Self-RAG and Corrective RAG | Part 3: Production Pipelines
Related Posts

Agentic RAG Pipeline — Multi-step Retrieval in Production
Build a full Plan-Retrieve-Evaluate-Synthesize pipeline. Unify vector search, web search, and SQL as agent tools. Add hallucination detection and source grounding.
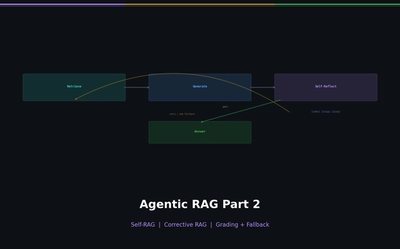
Self-RAG and Corrective RAG — The Agent Evaluates Its Own Retrieval
Implement Self-RAG reflection tokens and CRAG quality-based fallback. Build retry/fallback logic with LangGraph conditional edges.
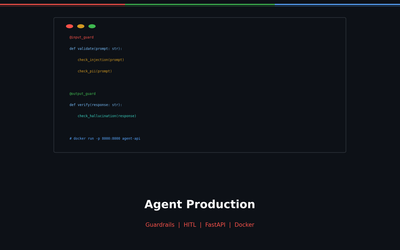
Agent Production — From Guardrails to Docker Deployment
Build safe agents with 3-layer Guardrails (Input/Output/Semantic), deploy with FastAPI + Docker. Includes HITL, rate limiting, and production monitoring checklist.