BPE vs Byte-level Tokenization: Why LLMs Struggle with Counting
Why do LLMs fail at counting letters in "strawberry"? The answer lies in tokenization. Learn how BPE creates variable granularity that hides character structure from models.
Introduction
Ask GPT-3.5: "Count each letter in KKKJJJSSS." It fails. "Spell 'abracadabra' backwards." It struggles. Even "What's the 5th character in 'abcdefghij'?" trips it up.
Modern models (GPT-4, Claude) handle these tasks well, but why were earlier models so bad at simple character-level operations? And why do they still occasionally fail in certain contexts?
The answer lies in tokenization strategy.
Tokenization is the process of breaking down text into smaller units (tokens) that the model can process. The choice between Byte Pair Encoding (BPE) and Byte-level tokenization has profound implications for how well a model understands text at a granular level.
What is BPE (Byte Pair Encoding)?
BPE is a compression algorithm adapted for tokenization. It works by:
- Starting with a vocabulary of individual characters
- Iteratively merging the most frequent pairs of tokens
- Building a vocabulary of subword units
Example:
Text: "playing playing playing"
Initial: ['p', 'l', 'a', 'y', 'i', 'n', 'g', ...]
After merges: ['play', 'ing', ...]WOW POINT 1: The "Variable Granularity" Phenomenon
BPE creates tokens of vastly different lengths. Common words like "the" become a single token, while rare words might be split into many tokens. This means:
- "strawberry" might be tokenized as
["straw", "berry"](2 tokens)
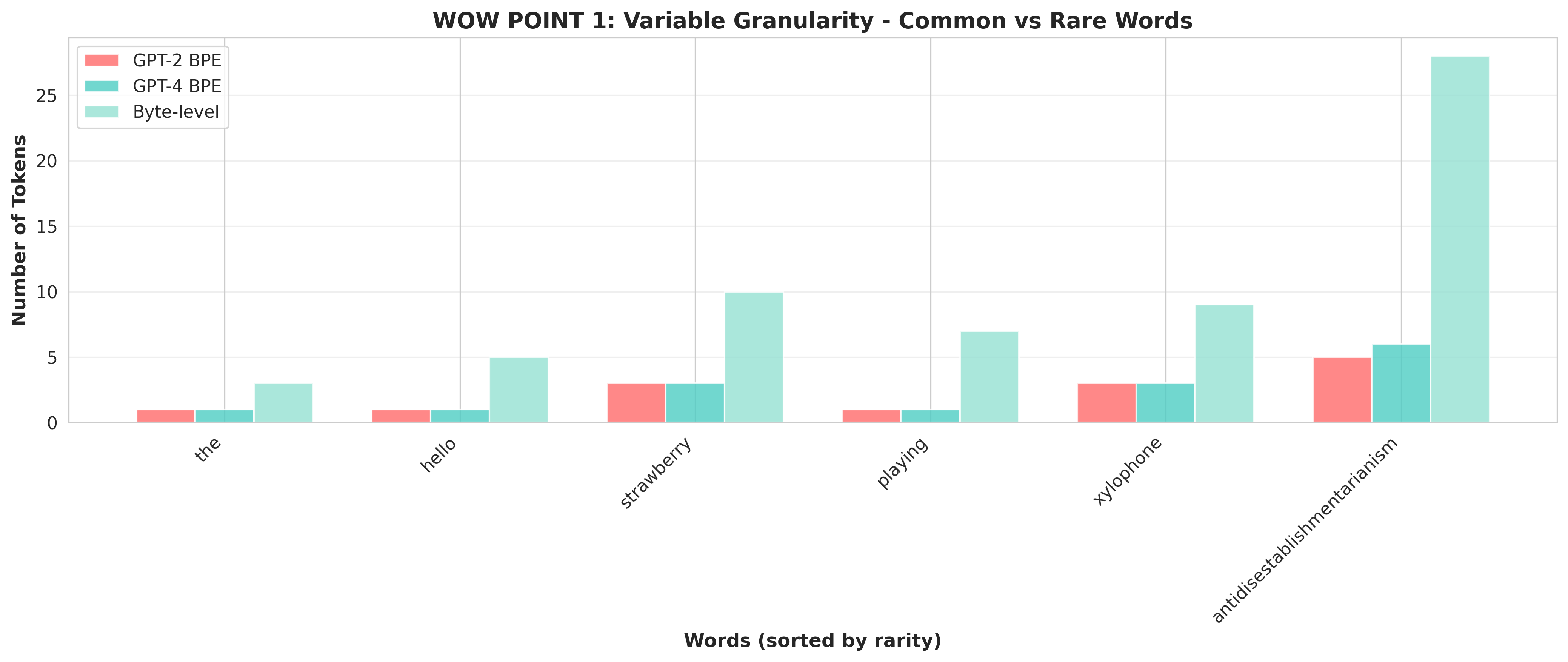
- "playing" might be
["play", "ing"](2 tokens) - But "xylophone" could be
["x", "yl", "oph", "one"](4+ tokens)
The model sees these as fundamentally different "word lengths" even though they're similar to humans!
This is why LLMs fail at counting letters—they never see individual characters for common words, only for rare ones.
What is Byte-level Tokenization?
Byte-level tokenization treats text as a sequence of bytes (0-255). Each byte is a token.
Advantages:
- Fixed granularity: Every character is represented consistently
- No unknown tokens: Any text can be encoded
- Better for character-level tasks: Spelling, counting, morphology
Disadvantages:
- Longer sequences: More tokens = more computation
- Less semantic compression: Can't leverage word-level patterns as efficiently
WOW POINT 2: Sequence Length Explosion
Let's compare token counts for the same text:
Text: "The quick brown fox jumps over the lazy dog."
- GPT-2 BPE: ~10 tokens
- Byte-level: ~45 tokens (one per character including spaces)
For a 1,000-word essay:
- BPE: ~750 tokens
- Byte-level: ~5,000+ tokens
This 5-7x increase in sequence length directly impacts:
- Memory consumption (quadratic in attention mechanism)
- Training cost
- Inference speed
The Real-World Impact on Model Capabilities
1. Mathematical Operations
Task: "Count the number of 'r's in 'strawberry'"
BPE model sees: ["straw", "berry"]
- The model has to "guess" that "straw" contains one 'r' and "berry" contains two
- It doesn't directly observe the characters
Byte-level model sees: ['s','t','r','a','w','b','e','r','r','y']
- Each 'r' is explicitly visible
- Counting becomes a pattern matching task
WOW POINT 3: The Spelling Paradox
BPE models are worse at spelling common words than rare ones!
Why?
- Common words are single tokens → model never learns internal structure
- Rare words are split into characters → model sees the spelling
Try asking ChatGPT to spell "because" backwards vs spelling "xylophone" backwards. The rare word often works better!
2. Cross-lingual Performance
BPE tokenizers trained on English data struggle with non-Latin scripts:
- English "hello": 1 token
- Chinese "你好": 2-4 tokens (if trained on English-heavy corpus)
- Korean "안녕하세요": 5-10 tokens
Byte-level tokenization treats all languages equally—every byte is a byte, whether it's English, Chinese, or emoji.
WOW POINT 4: The Compression Inequality
BPE creates a compression bias favoring the training data's language distribution:
| Language | Avg tokens per word (GPT-2) |
|---|---|
| English | 1.3 |
| Spanish | 1.5 |
| Chinese | 2.5 |
| Thai | 3.2 |
This means models need to process 2-3x more tokens for the same semantic content in non-Latin languages, leading to:
- Higher inference costs
- Context window "wasted" on encoding overhead
- Potentially degraded performance
Hybrid Approaches: The Best of Both Worlds?
Modern models like GPT-4 and Llama use variations that try to balance both:
- Character fallback: BPE with byte-level encoding for unknown sequences
- Multi-granularity: Mix of word-level, subword, and character tokens
- Language-specific tokenizers: Separate vocabularies for different scripts
WOW POINT 5: The Vocabulary Size Sweet Spot
Bigger vocabulary isn't always better:
- GPT-2: 50,257 tokens
- GPT-3: 50,257 tokens (same!)
- GPT-4: ~100,000 tokens (estimated)
- Llama 2: 32,000 tokens
Why not 1 million tokens?
- Embedding matrix cost: vocab_size × hidden_dim parameters
- Softmax computation: More tokens = slower generation
- Training data requirements: Rare tokens need sufficient examples
But byte-level has only 256 tokens! The embedding layer is tiny, but sequence lengths balloon.
Practical Implications for Developers
When BPE Fails You
- Character-level operations (counting, reversing, spelling)
- Multilingual applications with diverse scripts
- Code tokenization (variable names, special characters)
- Tasks requiring fine-grained text manipulation
When BPE Wins
- Long-context understanding (fewer tokens = longer context)
- General language understanding
- Semantic tasks (summarization, QA, reasoning)
- Efficient inference (fewer tokens = faster)
Conclusion
The choice between BPE and byte-level tokenization isn't about which is "better"—it's about trade-offs:
- BPE: Efficient, semantically aware, but struggles with character-level understanding
- Byte-level: Universal, consistent granularity, but computationally expensive
The future likely lies in adaptive tokenization: models that can dynamically choose granularity based on the task, or architectural innovations that make byte-level sequences as efficient as BPE.
Understanding tokenization is crucial because it's the lens through which the model sees the world. A model can't count letters it never sees. A model can't spell words it treats as atomic units. The tokenization strategy fundamentally shapes—and limits—what the model can learn.
Key Takeaways:
- BPE creates variable-length tokens that hide character structure from the model
- Byte-level tokenization maintains granularity but increases sequence length 5-7x
- LLMs struggle with counting/spelling because common words are single tokens
- BPE tokenizers create compression inequality across languages
- The vocabulary size sweet spot balances embedding cost with sequence length
Subscribe to Newsletter
Related Posts

VibeTensor: Can AI Build a Deep Learning Framework from Scratch?
NVIDIA researchers released VibeTensor, a complete deep learning runtime generated by LLM-based AI agents. With over 60,000 lines of C++/CUDA code written by AI, we analyze the possibilities and limitations this project reveals.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.