SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.
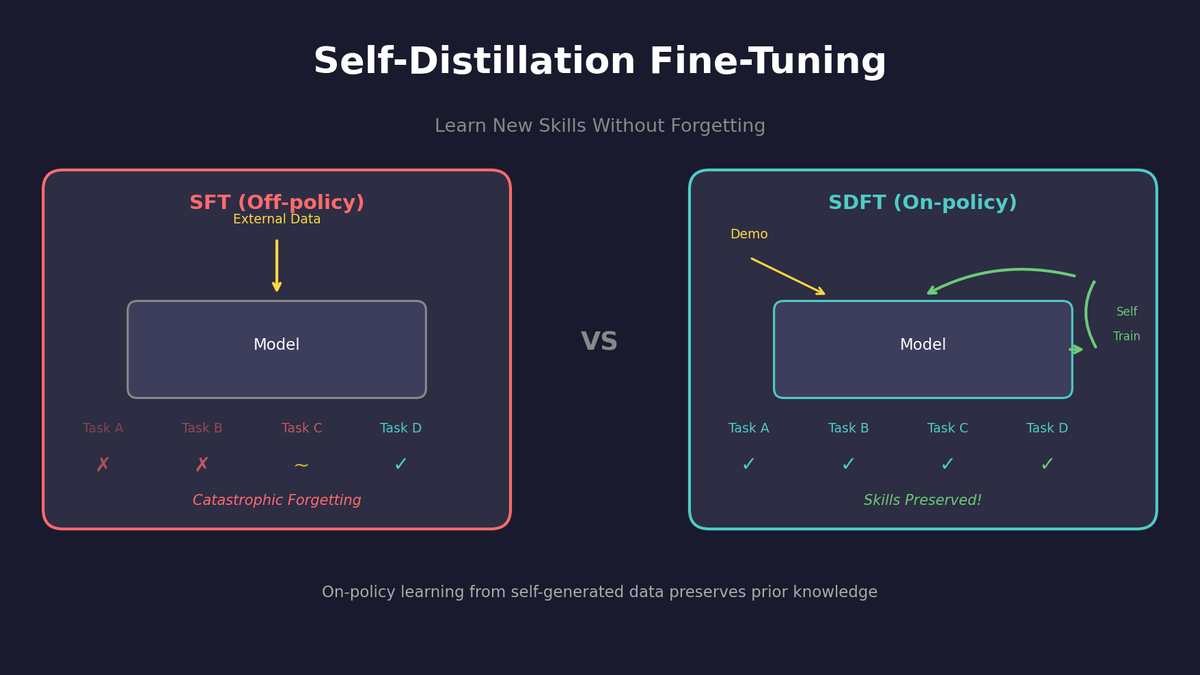
SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.
TL;DR
- Problem: Traditional SFT causes catastrophic forgetting when learning new tasks
- Solution: SDFT (Self-Distillation Fine-Tuning)
Related Posts

Models & Algorithms
Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

Models & Algorithms
YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.

Models & Algorithms
RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.