QLoRA + 한국어 — T4 한 장으로 7B 모델을 한국어 전문가로 만들기
QLoRA(4-bit NormalFloat + LoRA)로 T4 16GB에서 Qwen 2.5 7B 파인튜닝. 한국어 데이터셋 구축 가이드, NF4/Double Quantization/Paged Optimizer 원리, Wandb 모니터링.
QLoRA + 한국어 — T4 한 장으로 7B 모델을 한국어 전문가로 만들기
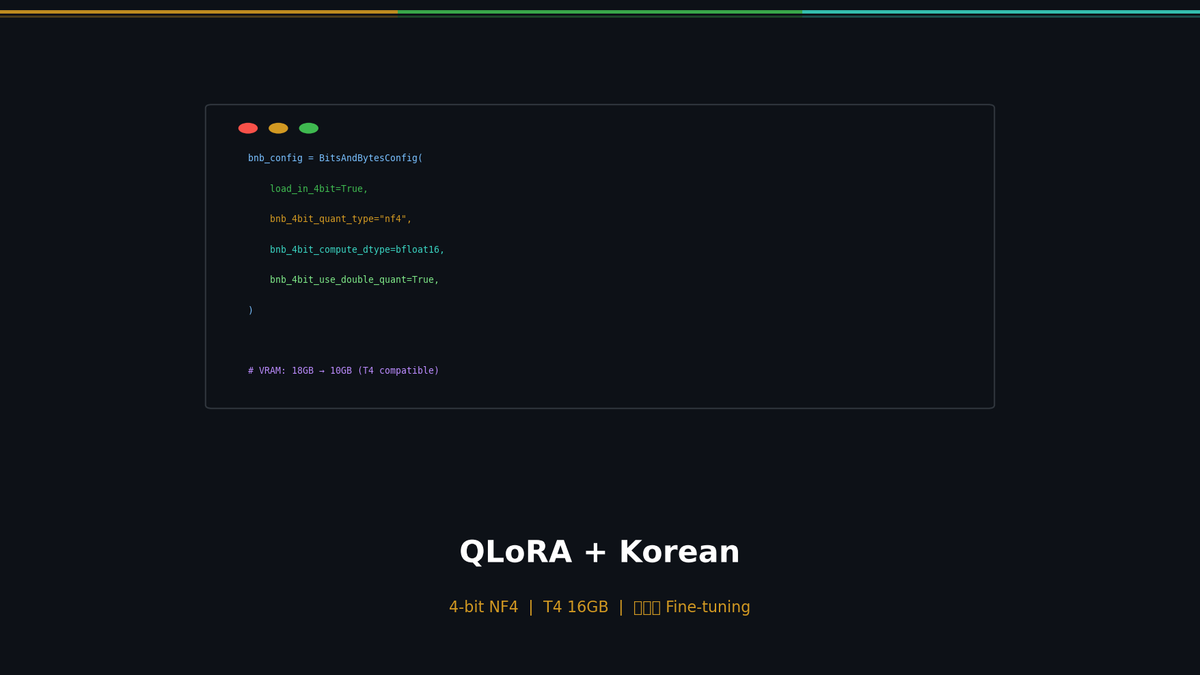
Part 1에서 LoRA의 원리와 Qwen 2.5 7B 파인튜닝을 다뤘습니다. RTX 3090(24GB)에서 약 18GB VRAM이 필요했습니다. 이번 글에서는 QLoRA로 T4 16GB 한 장까지 줄이고, 한국어 데이터셋을 구축해서 실제로 한국어 응답 품질을 끌어올립니다.
시리즈: Part 1: LoRA 이론 | Part 2 (이 글) | Part 3: 평가 + 배포
QLoRA: 메모리의 한계를 뚫다
LoRA가 학습 파라미터를 99.8% 줄였다면, QLoRA는 모델 자체의 메모리까지 줄입니다.
관련 포스트

Models & Algorithms
Agentic RAG 파이프라인 — 멀티스텝 검색의 프로덕션 적용
Plan-Retrieve-Evaluate-Synthesize 풀 파이프라인 구현. Vector + Web + SQL을 Tool로 통합하고, 환각 탐지와 소스 그라운딩으로 신뢰도를 확보합니다.
Models & Algorithms
Self-RAG과 Corrective RAG — Agent가 자기 검색을 평가하는 법
Self-RAG의 reflection token 메커니즘과 CRAG의 품질 기반 폴백 전략을 구현합니다. LangGraph conditional edge로 retry/fallback 로직 구성.

Models & Algorithms
Agentic RAG 첫걸음 — Query Routing과 Adaptive Retrieval
Naive RAG의 한계를 진단하고, 쿼리 의도를 분류해 최적의 검색 소스로 라우팅하는 Agent를 LangGraph로 구현합니다. Adaptive Retrieval로 불필요한 검색을 제거하는 방법까지.