QLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
Fine-tune Qwen 2.5 7B on a T4 16GB using QLoRA (4-bit NormalFloat + LoRA). Korean dataset preparation guide, NF4/Double Quantization/Paged Optimizer explained, Wandb monitoring.
QLoRA + Custom Dataset — Fine-tune 7B on a Single T4 GPU
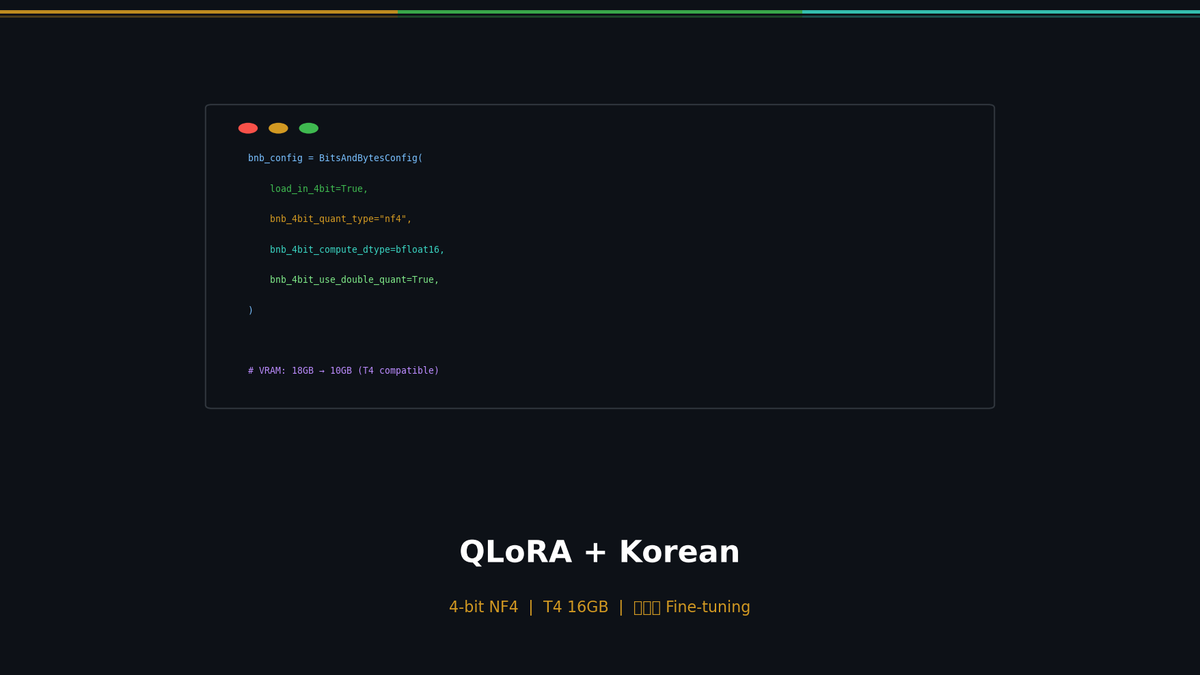
In Part 1, we covered the theory behind LoRA and fine-tuned Qwen 2.5 7B. That required about 18GB of VRAM on an RTX 3090 (24GB). In this post, we use QLoRA to bring that down to a single T4 with 16GB, and build a Korean-language dataset to meaningfully improve the model's Korean response quality.
Series: Part 1: LoRA Theory | Part 2 (this post) | Part 3: Eval + Deploy
QLoRA: Breaking Through the Memory Barrier
If LoRA reduced trainable parameters by 99.8%, QLoRA goes further and reduces the memory footprint of the model itself.
Related Posts

Agentic RAG Pipeline — Multi-step Retrieval in Production
Build a full Plan-Retrieve-Evaluate-Synthesize pipeline. Unify vector search, web search, and SQL as agent tools. Add hallucination detection and source grounding.
Self-RAG and Corrective RAG — The Agent Evaluates Its Own Retrieval
Implement Self-RAG reflection tokens and CRAG quality-based fallback. Build retry/fallback logic with LangGraph conditional edges.

Why Agentic RAG? — Query Routing and Adaptive Retrieval
Diagnose naive RAG limitations, classify query intent, and route to the optimal retrieval source with LangGraph. Implement adaptive retrieval that skips unnecessary searches.