ViBT: The Beginning of Noise-Free Generation, Vision Bridge Transformer (Paper Review)
Analyzing ViBT's core technology and performance that transforms images/videos without noise using a Vision-to-Vision paradigm with Brownian Bridge.
ViBT: The Beginning of Noise-Free Generation, Vision Bridge Transformer
Introduction
"Why do we need to go through noise to edit an image?"
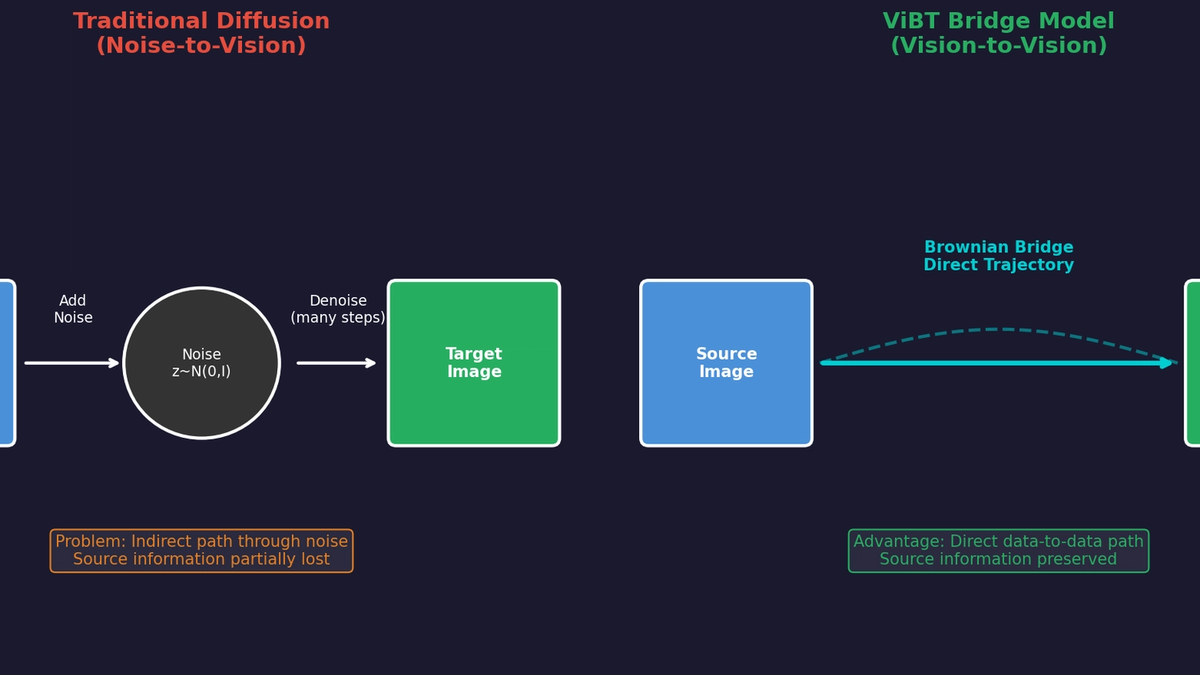
Existing Diffusion models always follow the Noise-to-Vision paradigm, even for conditional generation tasks. For image style transfer, editing, and Depth-to-Video, they first create noise and then generate results from that noise.
But if you think about it, this seems strange. When the source and result are similar, why go through a noise state that destroys all information?
ViBT (Vision Bridge Transformer) starts from this question. Using a mathematical framework called Brownian Bridge, it models probabilistic paths that directly connect source to target. A Vision-to-Vision paradigm that transforms data to data without going through noise.
1. Core Problem: Why Go Through Noise?
1.1 Inefficiency of Existing Diffusion
Let's examine how existing Conditional Diffusion models work:
Problems:
- Information Loss: Source image information is completely destroyed into noise and must be recovered through conditions.
- Non-intuitive Path: Even for style transfer with similar outputs, it goes through a completely different noise state.
- Inference Cost: Requires a separate Condition Encoder, and these tokens increase computation.
1.2 Need for Vision-to-Vision Paradigm
ViBT's new perspective:
"If source and target are similar, why not just learn a path that directly connects them?"
This is the core idea of Bridge Models.
2. Brownian Bridge: Mathematical Foundation
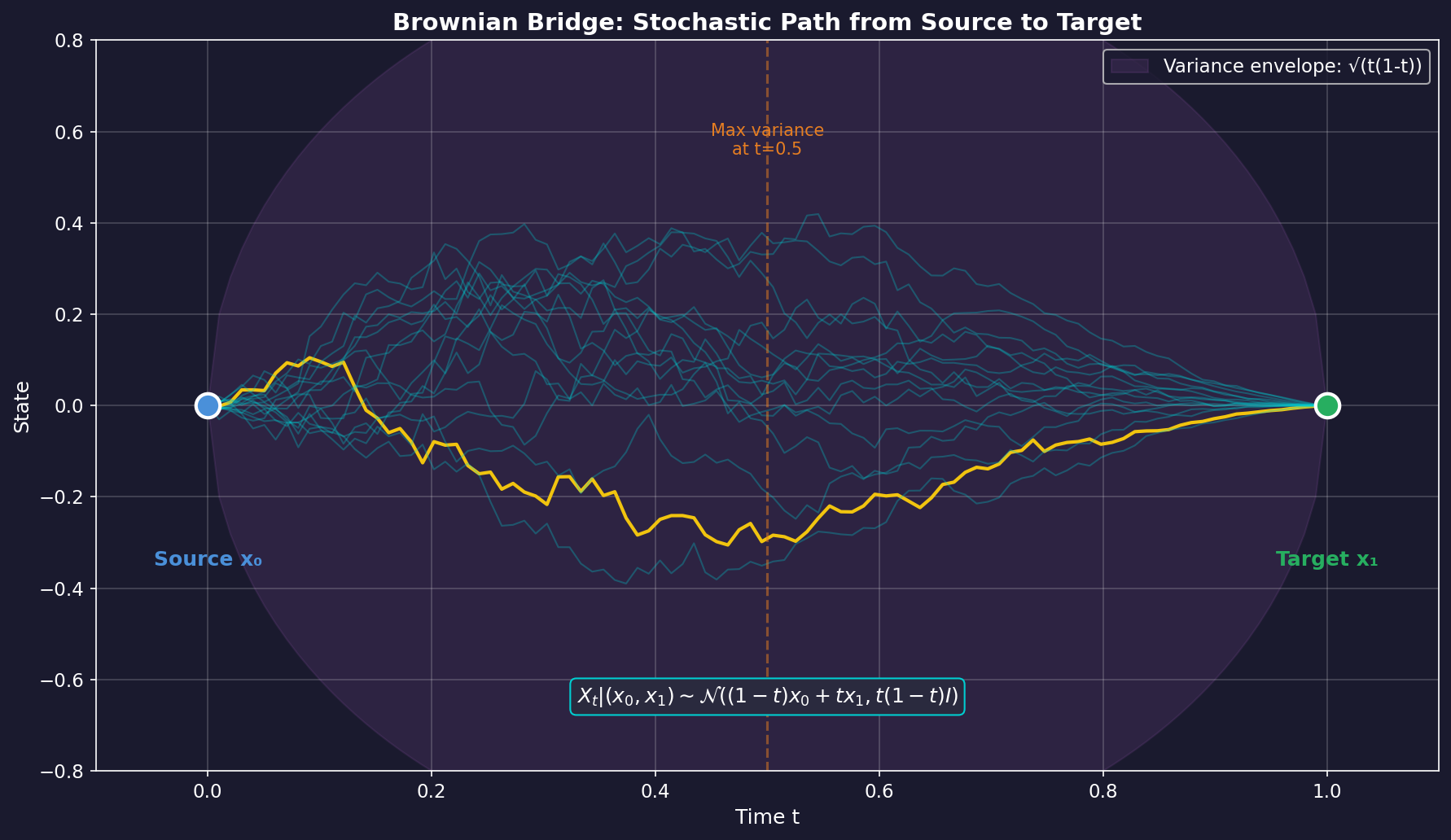
2.1 What is Brownian Bridge?
Brownian Bridge is a stochastic process with fixed endpoints. While regular Brownian Motion is a "free random walk" with only a starting point, Brownian Bridge is a "constrained random walk" with both start and end points fixed.
Mathematical Definition:
Given source and target , the intermediate state at time follows:
Key Properties:
- : Exactly (source)
- : Exactly (target)
- : Intermediate state, maximum variance
2.2 Why is Bridge Effective?
Crucial difference from Diffusion:
| Aspect | Diffusion | Bridge |
|---|---|---|
| Start | Pure noise $z \sim N(0,I)$ | Source data $x_0$ |
| End | Target data $x_1$ | Target data $x_1$ |
| Information Flow | Noise → Data | Data → Data |
| Source Usage | Only as condition | Directly as path start |
Bridge models directly utilize source information as part of the path, making them more efficient for conditional generation.
3. ViBT's Technical Innovations
3.1 Problem: Instability in Large-Scale Training
Scaling Bridge models to 20B parameters causes serious problems.
Velocity Target Divergence:
The instantaneous velocity of Bridge is defined as:
As , the denominator approaches 0, causing velocity to diverge. This diverges at rate, destabilizing training loss.
3.2 Solution: Stabilized Velocity Matching
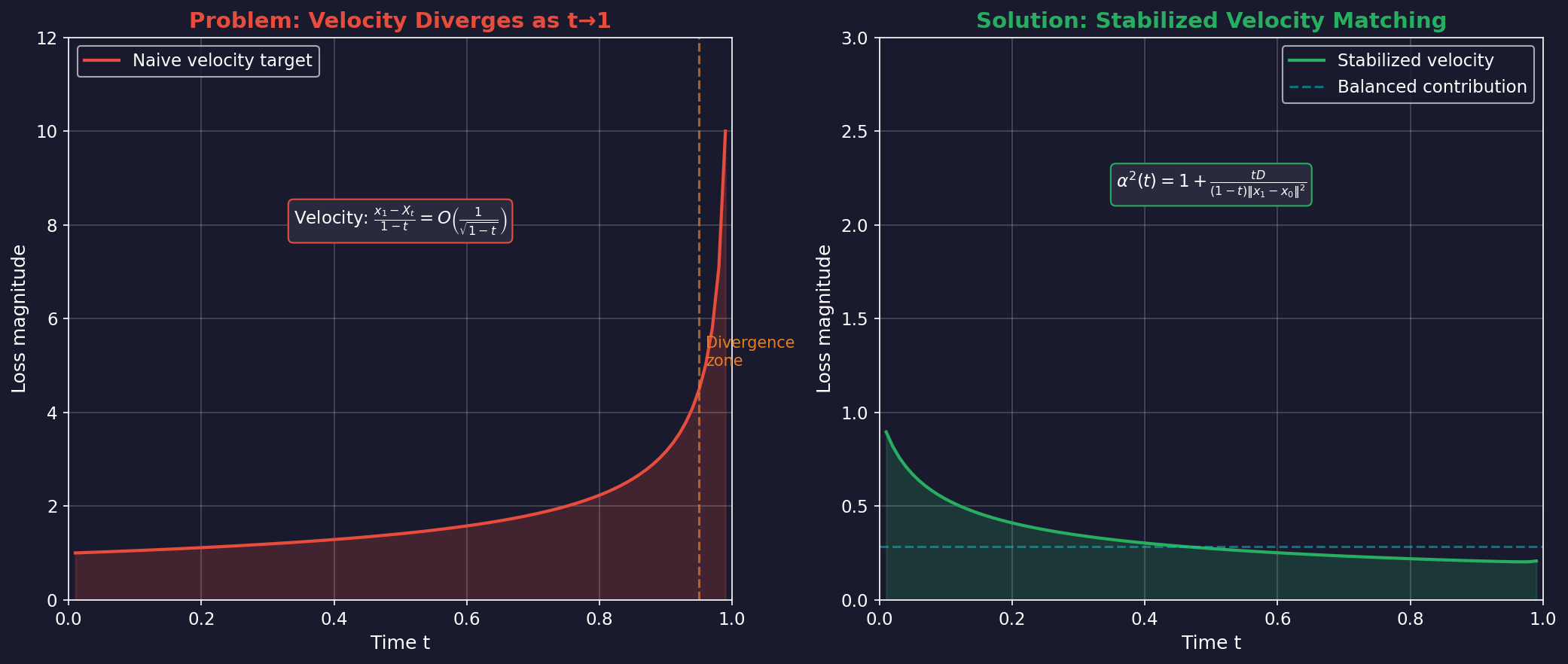
ViBT's key contribution is introducing a normalization factor α:
where is the latent dimension.
Stabilized Training Objective:
Effects:
- When is small: (same as before)
- As : grows to cancel diverging velocity
- Result: Balanced loss contributions across all timesteps
3.3 Variance-Corrected Sampling
Problems exist not only in training but also in inference.
Standard Euler-Maruyama Problem:
Standard discretization ignores Brownian Bridge's variance characteristics. In Bridge, variance should decrease as , but standard sampling doesn't reflect this.
ViBT's Corrected Sampling:
The key is multiplying the noise scale by :
- Early ( small): High stochasticity
- Late (): Low stochasticity for smooth convergence
4. Architecture and Training
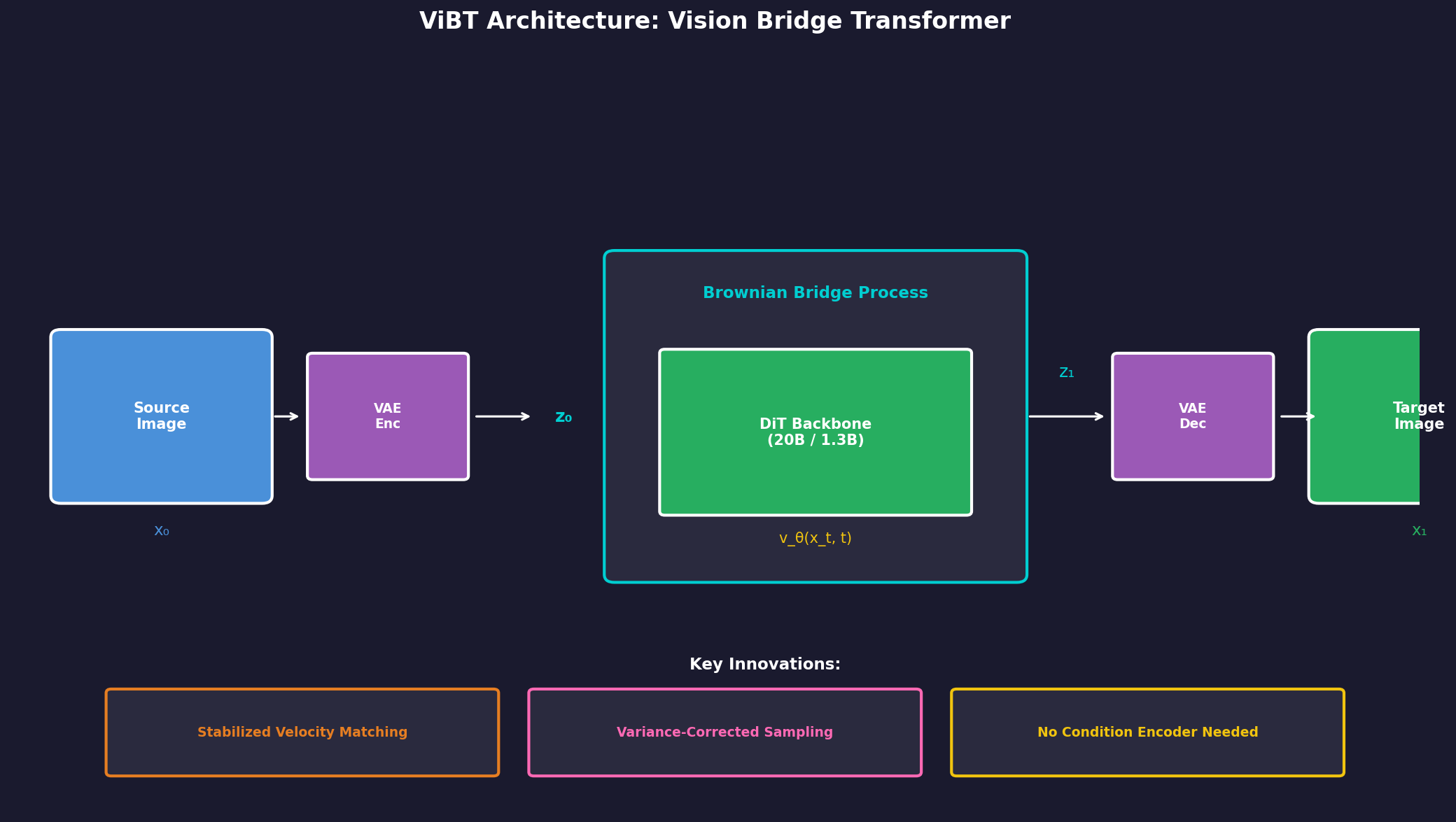
4.1 Model Configuration
ViBT builds on the DiT (Diffusion Transformer) architecture:
Image Model (20B):
- Base: Qwen-Image-Editing
- Fine-tuning: LoRA (rank 128)
- Training: 20,000 iterations, 1 H100 GPU
Video Model (1.3B):
- Base: Wan 2.1
- Fine-tuning: Full parameter
- Training: 50,000 iterations, 4 H100 GPUs
4.2 Training Data
| Task | Data Scale | Source |
|---|---|---|
| Image Editing | ~6K pairs | Open Images + Qwen3-VL generated |
| Video Stylization | 10K videos | Ditto-1M subset |
| Depth-to-Video | ~1K videos | Wan 2.2 generated + Depth Anything V2 |
Remarkably, strong performance was achieved with very little data.
5. Experimental Results
5.1 Benchmark Performance
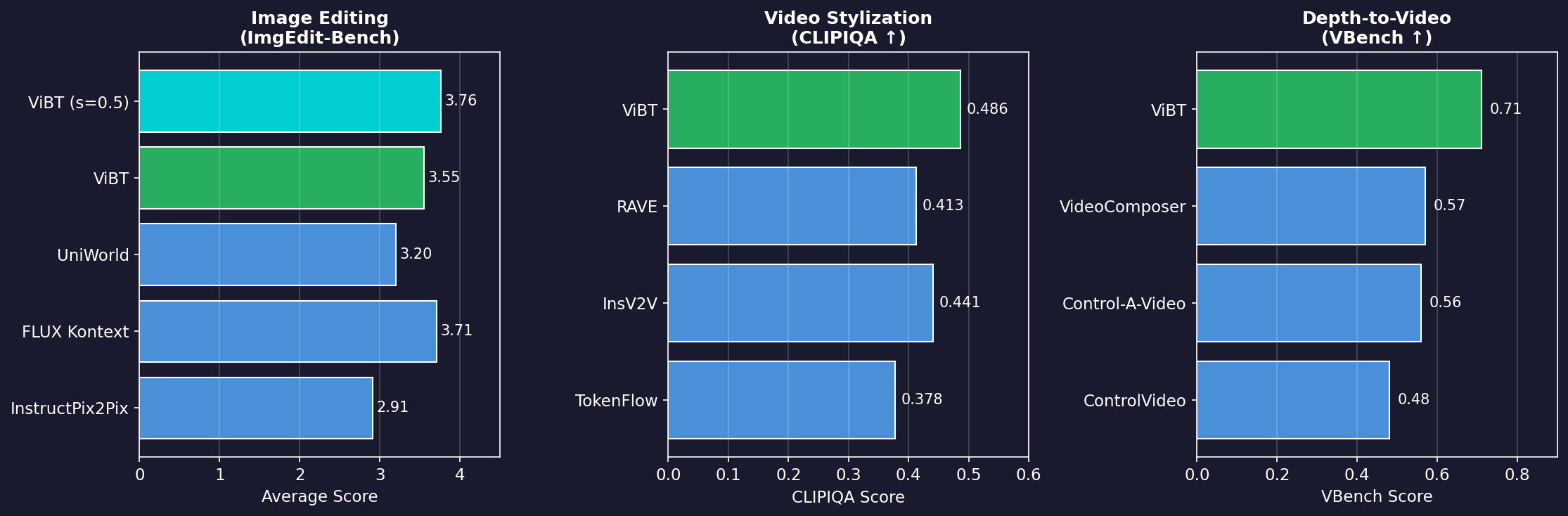
Image Editing (ImgEdit-Bench):
| Model | Average Score |
|---|---|
| InstructPix2Pix | 2.91 |
| FLUX Kontext | 3.71 |
| UniWorld | 3.20 |
| **ViBT** | 3.55 |
| **ViBT (s=0.5)** | **3.76** |
ViBT excels particularly in Object Addition (4.20) and Style Transfer (4.85).
Video Stylization:
| Model | CLIPIQA ↑ | MUSIQ ↑ |
|---|---|---|
| TokenFlow | 0.378 | 59.12 |
| InsV2V | 0.441 | 60.62 |
| RAVE | 0.413 | 62.53 |
| **ViBT** | **0.486** | **64.05** |
Depth-to-Video:
| Model | VBench ↑ | SSIM ↑ |
|---|---|---|
| ControlVideo | 0.48 | 0.312 |
| Control-A-Video | 0.56 | 0.369 |
| VideoComposer | 0.57 | 0.401 |
| **ViBT** | **0.71** | **0.429** |
5.2 Speed Comparison
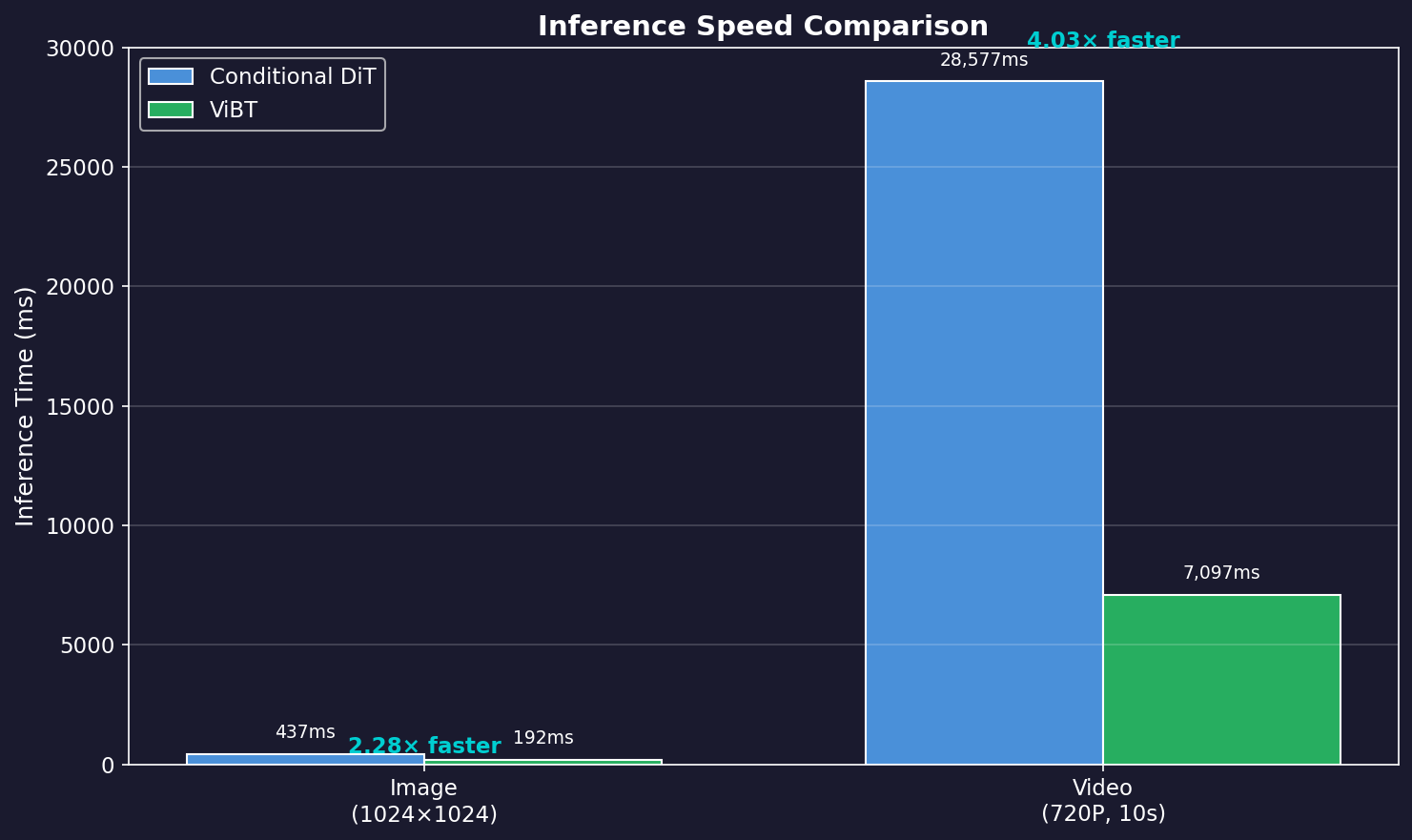
One of ViBT's biggest advantages is inference speed:
| Resolution | Conditional DiT | ViBT | Speedup |
|---|---|---|---|
| Image (1024²) | 437ms | 192ms | **2.28×** |
| Video (720P, 10s) | 28,577ms | 7,097ms | **4.03×** |
Secret to Speed Improvement:
- No Condition Encoder needed
- No additional conditioning tokens
- About 50% token reduction
6. Ablation Study: Impact of Noise Scale
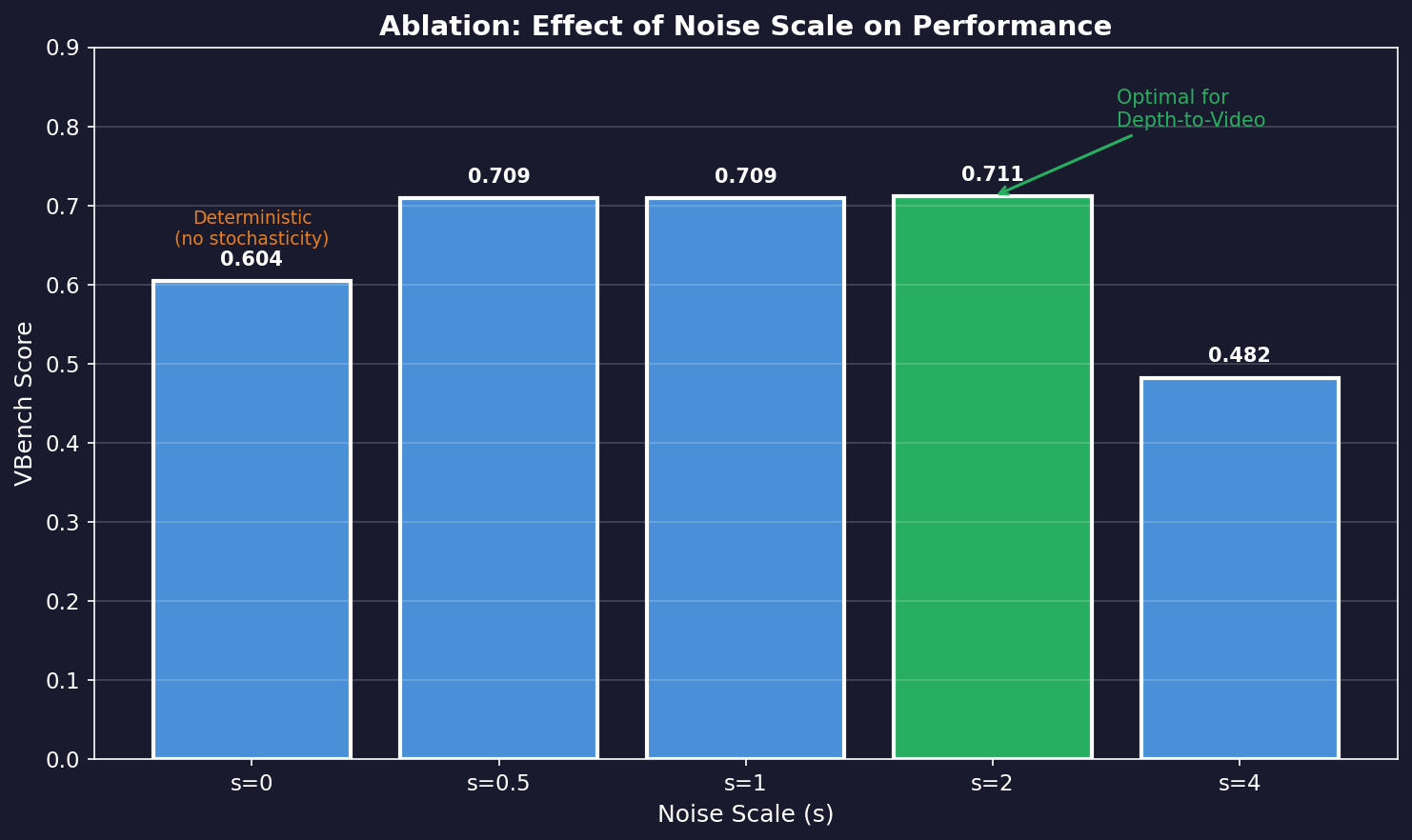
One interesting finding is that optimal noise scale differs by task.
| Noise Scale (s) | VBench Score |
|---|---|
| 0 (deterministic) | 0.604 |
| 0.5 | 0.709 |
| 1 | 0.709 |
| **2** | **0.711** |
| 4 | 0.482 |
Insights:
- (fully deterministic): Performance degradation
- Around : Optimal for Depth-to-Video
- : Optimal for Image Editing
- : Excessive stochasticity causes performance drop
This contradicts prior work claiming "extremely small noise scales are optimal."
7. Limitations and Future Directions
7.1 Current Limitations
- Task-specific noise scale tuning needed: No automatic method to find optimal scale yet.
- Complex structural changes: May have limitations when source and target are very different (e.g., completely different compositions).
7.2 Future Possibilities
- Universal Bridge Model: Handle various tasks with a single model
- Scaling further: Performance verification at 100B+ scale
- Real-time applications: Interactive editing through faster inference
8. Conclusion
ViBT proposes a paradigm shift in conditional generation:
- Noise-free Generation: Direct data-to-data transformation without going through noise
- Stabilized Training: Solving technical barriers for large-scale Bridge model training
- Efficiency: Up to 4× faster inference without Condition Encoder
Particularly impressive is achieving strong performance with very little training data (thousands of samples). This suggests Bridge models are inherently efficient structures for conditional generation.
ViBT's message that "generation is possible without noise" points to a new direction for future generative model research.
References
- Paper - arXiv:2511.23199: Tan et al., "Vision Bridge Transformer at Scale", 2025
- Project Page
- GitHub Repository
- HuggingFace Demo
Subscribe to Newsletter
Related Posts

SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.

Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.

YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.