

All Posts
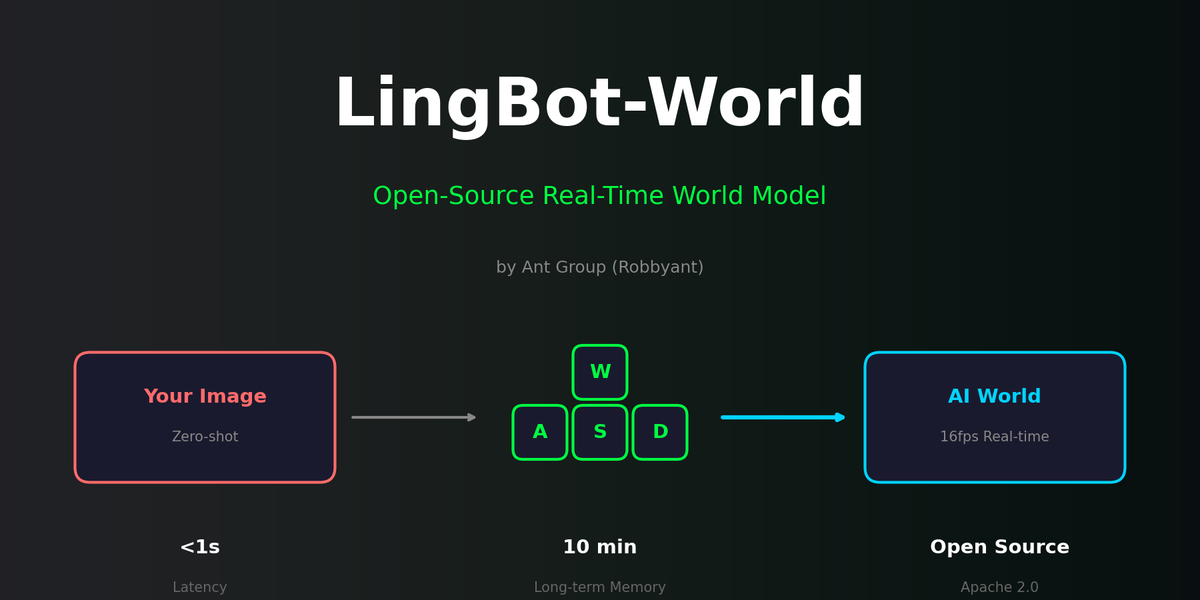
LingBot-World: Enter the AI-Generated Matrix
LingBot-World from Ant Group is the first high-performance real-time world model released as open source. AI generates worlds in real-time based on keyboard input - we analyze this revolutionary project.
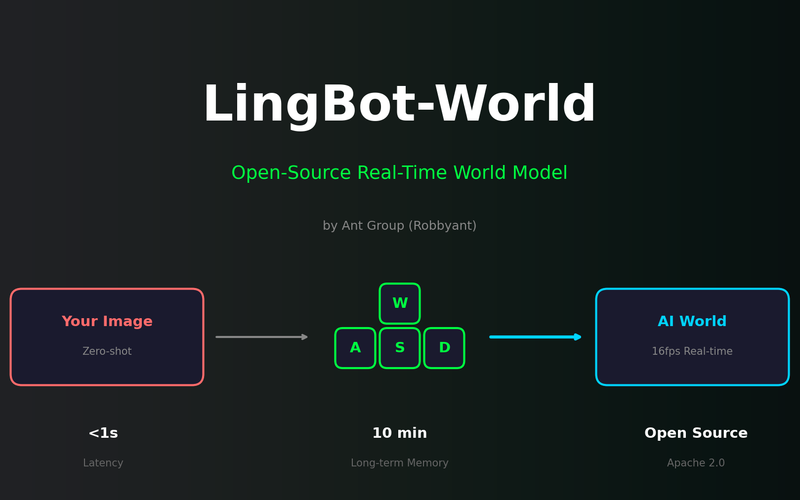
VibeTensor: Can AI Build a Deep Learning Framework from Scratch?
NVIDIA researchers released VibeTensor, a complete deep learning runtime generated by LLM-based AI agents. With over 60,000 lines of C++/CUDA code written by AI, we analyze the possibilities and limitations this project reveals.
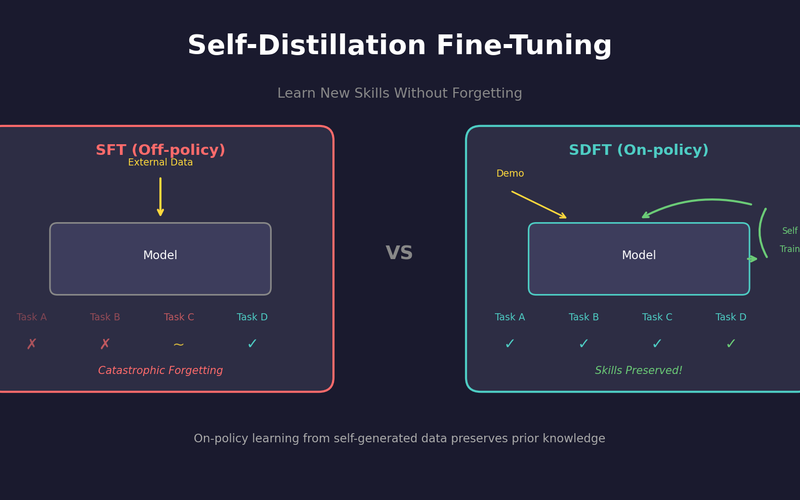
SDFT: Learning Without Forgetting via Self-Distillation
No complex RL needed. Models teach themselves to learn new skills while preserving existing capabilities.
Google Stitch MCP API Released: AI Agents Can Now Directly Manipulate UI Designs
Google Labs' experimental AI UI design tool Stitch now officially supports MCP (Model Context Protocol) servers. You can now directly manipulate Stitch projects from AI coding tools like Cursor, Claude Code, and Gemini CLI.
Qwen3-Max-Thinking Snapshot Release: A New Standard in Reasoning AI
The recent trend in the LLM market goes beyond simply learning "more data" — it's now focused on "how the model thinks." Alibaba Cloud has released an API snapshot (qwen3-max-2026-01-23) of its most powerful model, Qwen3-Max-Thinking.
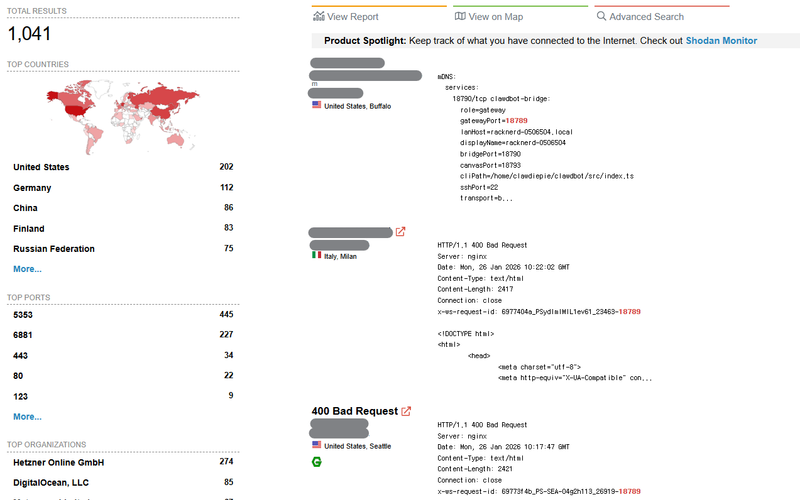
Securing ClawdBot with Cloudflare Tunnel
Learn about the security risks of exposed ClawdBot instances on Shodan and how to secure them using Cloudflare Tunnel.

Integrating Google Stitch MCP with Claude Code: Automate UI Design with AI
Learn how to connect Google Stitch with Claude Code via MCP to generate professional-grade UI designs from text prompts.

YOLO26: Upgrade or Hype? The Complete Guide
Analyzing YOLO26's key features released in January 2026, comparing performance with YOLO11, and determining if it's worth upgrading through hands-on examples.

The Blind Spot of Vibe Coding: Checking Your Server Without a Laptop
Ideas always come when you don't have your laptop

30-Minute Behavioral QA Before Deploy: 12 Bugs That Actually Break Vibe-Coded Apps
Session, Authorization, Duplicate Requests, LLM Resilience — What Static Analysis Can't Catch

The Real Reason Launches Fail: Alignment, Accountability, Operations
AI Project Production Guide for Teams and Organizations

Production Survival Guide for Vibe Coders
5 Non-Negotiable Standards for Enterprise Deployment

5 Reasons Your Demo Works But Production Crashes
Common patterns across AI, RAG, and ML projects — why does "it worked fine" fall apart in production?

RAG Evaluation: Beyond Precision/Recall
"How do I know if my RAG is working?" — Precision/Recall aren't enough. You need to measure Faithfulness, Relevance, and Context Recall to see the real quality.

Retrieval Planning: ReAct vs Self-Ask vs Plan-and-Solve
Now that we've diagnosed Query Planning failures, it's time to fix them. Let's compare when each of these three patterns shines.

Query Planning Failures in Multi-hop RAG: Patterns and Solutions
You added Query Decomposition, but why does it still fail? Decomposition is just the beginning—the real problems emerge in Sequencing and Grounding.

Multi-hop RAG: Why It Still Fails After Temporal RAG
You added Temporal RAG, but "who is my boss's boss?" still returns wrong answers. RAG now understands time, but it still doesn't know "what to search for next."

Temporal RAG: Why RAG Always Gets 'When' Questions Wrong
"Who was the CEO in 2023?" "What about now?" — Why RAG gives wrong answers to these simple questions, and how to fix it.

GraphRAG: Microsoft's Global-Local Dual Search Strategy
Why can't traditional RAG answer "What are the main themes in these documents?" Microsoft Research's GraphRAG reveals the secret of community-based search.

Building GraphRAG with Neo4j + LangChain
Automatically convert natural language questions to Cypher queries and generate accurate answers using relationship data from your graph database.

Overcoming RAG Limitations with Knowledge Graphs: Ontology-Based Retrieval Systems
Vector search alone isn't enough. Upgrade your RAG system with Knowledge Graphs that understand entity relationships.

Claude Code in Practice (5): Model Mix Strategy
Tests with Haiku, refactoring with Sonnet, architecture with Opus. Learn how to optimize both cost and quality by selecting the right model for each task.

Claude Code in Practice (4): Building MCP Servers
What if Claude could read Jira tickets, send Slack messages, and query your database? Learn how to extend Claude's capabilities with MCP servers.

Claude Code in Practice (3): Building Team Standards with Custom Skills
Complete new hire onboarding with just /setup-dev. Automate deployment with a single /deploy staging. Learn how to create team-specific commands with Custom Skills.

Claude Code in Practice (2): Automating Workflows with Hooks
What if Claude automatically ran lint, tests, and security scans every time it generated code? Learn how to automate team workflows with Hooks.

Claude Code in Practice (1): Context is Everything
One CLAUDE.md file can dramatically change your AI coding assistant's performance. Learn how to keep Claude on track in large-scale projects.

Automating Data Quality Checks: SQL Templates for NULL, Duplicates, and Consistency
SQL checklist to catch data quality issues early. NULL checks, duplicates, referential integrity, range validation.

Anomaly Detection in SQL: Finding Outliers with Z-Score and IQR
Automatically detect abnormal data with SQL. Implement Z-Score, IQR, and percentile-based outlier detection.

Time Series Analysis in SQL: Mastering Moving Averages, YoY, and MoM Trends
Can't see the revenue trend? How to implement moving averages, YoY, and MoM comparisons in SQL.

A/B Test Analysis in SQL: Calculating Statistical Significance Yourself
Analyze A/B test results with SQL alone. Z-test, confidence intervals, and sample size calculation.

Advanced Funnel Analysis: Finding Conversion Rates and Drop-off Points in SQL
Pinpoint exactly where users drop off with SQL. Everything about calculating step-by-step conversion rates.

Building Cohort Analysis in SQL: The Complete Guide to Retention
Build cohort analysis without GA4. Implement monthly retention and N-day retention directly in SQL.

Mastering CTE: Escape Subquery Hell Once and For All
One WITH clause transforms unreadable queries into clear, logical steps. Recursive CTEs handle hierarchies with ease.

CFG-free Distillation: Fast Generation Without Guidance
Eliminating the 2x computational cost of CFG. Achieving same quality with single forward pass.

Consistency Models: A New Paradigm for 1-Step Generation
Single-step generation without iterative sampling. OpenAI's innovative approach using self-consistency property.

SDE vs ODE: Mathematical Foundations of Score-based Diffusion
Stochastic vs Deterministic. A deep dive into Score-based SDEs and Probability Flow ODEs, the theoretical foundations of DDPM and DDIM.

Stable Diffusion 3 & FLUX: Complete Guide to MMDiT Architecture
From U-Net to Transformer. A deep dive into MMDiT architecture treating text and image equally, plus Rectified Flow and Guidance Distillation.

Rectified Flow: Straightening Paths Toward 1-Step Generation
Flow Matching still too slow? Reflow straightens trajectories for 1-step generation. The core technique behind SD3 and FLUX.

Flow Matching vs DDPM: Why ODE Beats SDE in Diffusion Models
DDPM needs 1000 steps, Flow Matching needs 10. The mathematics of straight-line generation. Comparing SDE curved paths vs ODE straight paths.

Claude Can't Read Your Database? Connect It Directly with MCP
Build an MCP server in 50 lines of Python to connect Claude to your database. Execute SQL queries with natural language.

Build Your Own Marketing Funnel Without GA4 — Sessions, Attribution, ROAS in SQL
Learn how to implement sessions, attribution, funnels, and ROAS with pure SQL — no expensive analytics tools needed.

"We Need Python for This" — Handling Pivot, JSON, UTM, RFM All in SQL
Learn practical patterns to handle Pivot, JSON parsing, UTM extraction, and RFM segmentation with a single SQL query instead of 100 lines of Python.
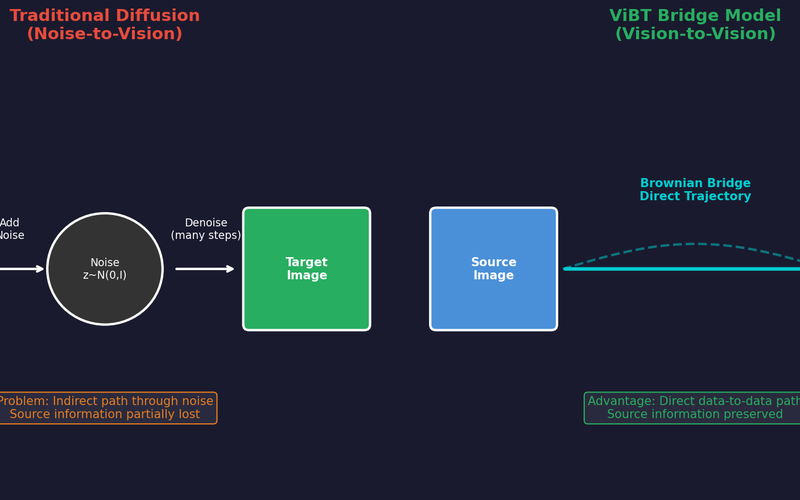
ViBT: The Beginning of Noise-Free Generation, Vision Bridge Transformer (Paper Review)
Analyzing ViBT's core technology and performance that transforms images/videos without noise using a Vision-to-Vision paradigm with Brownian Bridge.
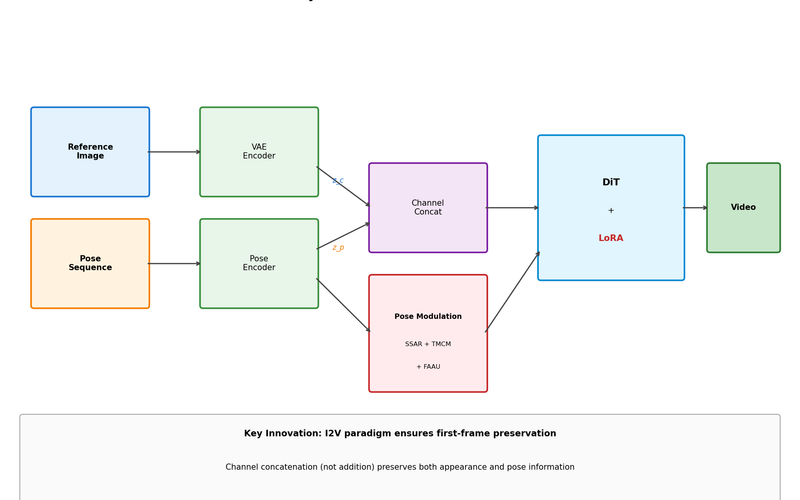
SteadyDancer Complete Analysis: A New Paradigm for Human Image Animation with First-Frame Preservation
Make a photo dance - why existing methods fail and how SteadyDancer solves the identity problem by guaranteeing first-frame preservation through the I2V paradigm.
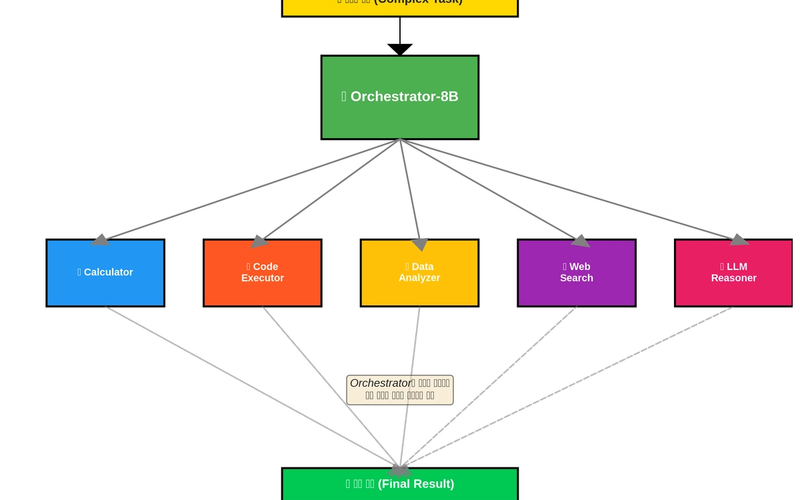
Still Using GPT-4o for Everything? (How to Build an AI Orchestra & Save 90%)
An 8B model as conductor routes queries to specialized experts based on difficulty. ToolOrchestra achieves GPT-4o performance at 1/10th the cost using a Compound AI System approach.
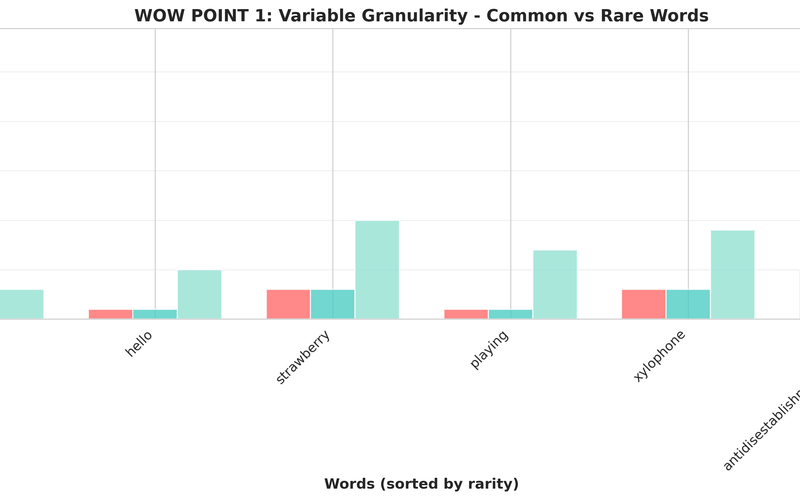
BPE vs Byte-level Tokenization: Why LLMs Struggle with Counting
Why do LLMs fail at counting letters in "strawberry"? The answer lies in tokenization. Learn how BPE creates variable granularity that hides character structure from models.

The Real Bottleneck in RAG Systems: It's Not the Vector DB, It's Your 1:N Relationships
Many teams try to solve RAG accuracy problems by tuning their vector database. But the real bottleneck is chunking that ignores the relational structure of source data.

"Can SQL Do This?" — Escaping Subquery Hell with Window Functions
LAG, LEAD, RANK for month-over-month, rankings, and running totals

One Wrong JOIN and Your Revenue Doubles — The Complete Guide to Accurate Revenue Aggregation
Row Explosion in 1:N JOINs and how to aggregate revenue correctly

Why Does Your SQL Query Take 10 Minutes? — From EXPLAIN QUERY PLAN to Index Design
EXPLAIN, indexes, WHERE vs HAVING — diagnose and optimize slow queries yourself

SANA: O(n²)→O(n) Linear Attention Generates 1024² Images in 0.6 Seconds
How Linear Attention solved Self-Attention quadratic complexity. The secret behind 100x faster generation compared to DiT.

PixArt-α: How to Cut Stable Diffusion Training Cost from $600K to $26K
23x training efficiency through Decomposed Training strategy. Making Text-to-Image models accessible to academic researchers.

DiT: Replacing U-Net with Transformer Finally Made Scaling Laws Work (Sora Foundation)
U-Net shows diminishing returns when scaled up. DiT improves consistently with size. Complete analysis of the architecture behind Sora.

From 512×512 to 1024×1024: How Latent Diffusion Broke the Resolution Barrier
How Latent Space solved the memory explosion problem of pixel-space diffusion. Complete analysis from VAE compression to Stable Diffusion architecture.

DDIM: 20x Faster Diffusion Sampling with Zero Quality Loss (1000→50 Steps)
Use your DDPM pretrained model as-is but sample 20x faster. Mathematical derivation of probabilistic→deterministic conversion and eta parameter tuning.

DDPM Math Walkthrough: Deriving Forward/Reverse Process Step by Step
Generate high-quality images without GAN mode collapse. Derive every equation from β schedule to loss function and truly understand how DDPM works.

Why Your Translation Model Fails on Long Sentences: Context Vector Bottleneck Explained
BLEU score drops by half when sentences exceed 40 words. Deep analysis from information theory and gradient flow perspectives, proving why Attention is necessary.

Bahdanau vs Luong Attention: Which One Should You Actually Use? (Spoiler: Luong)
Experimental comparison of additive vs multiplicative attention performance and speed. Why Luong is preferred in production, proven with code.

Building Seq2Seq from Scratch: How the First Neural Architecture Solved Variable-Length I/O
How Encoder-Decoder architecture solved the fixed-size limitation of traditional neural networks. From mathematical foundations to PyTorch implementation.

AdamW vs Lion: Save 33% GPU Memory While Keeping the Same Performance
How Lion optimizer saves 33% memory compared to AdamW, and the hyperparameter tuning guide for real-world application. Use it wrong and you lose.